内容持续更新中
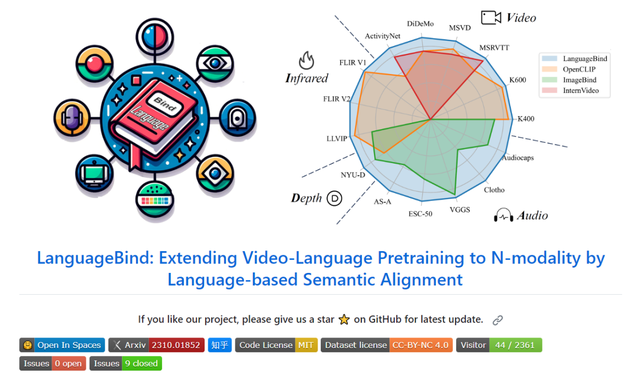
还自建首个有深度和红外的大规模多模态数据集 AI4Happiness 投稿 量子位 | 公众号 QbitAI 北大联合腾讯打造了一个多模态15边形战士! 以语言为中心,“拳打脚踢”视频、音频、深度、红…
还有开放服务平台 梦晨 发自 凹非寺量子位 | 公众号 QbitAI 大模型搞多模态,做文字、图像、音视频这几样就够了? 中科院自动化所说不: 我们还加入了3D点云和更多传感器信号。 国产大模型新成员…
3天训完130亿参数通用VLM 一个北大投稿 发送至 凹非寺 量子位 | 公众号 QbitAI 训完130亿参数通用视觉语言大模型,只需3天! 北大和中山大学团队又出招了——在最新研究中,研究团队提出…
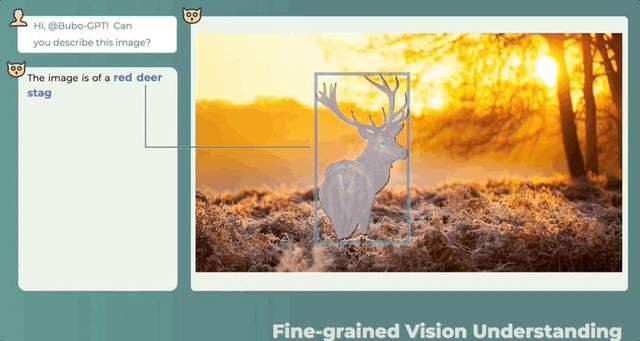
还认识班卓琴? 西风 发自 凹非寺量子位 | 公众号 QbitAI 字节大模型,BuboGPT来了。 支持文本、图像、音频三种模态,做到细粒度的多模态联合理解。 答哪指哪,什么讲了什么没讲,一目了然:…
智能体即大脑 赵浩然 投稿 量子位 | 公众号 QbitAI 进入多模态时代,大模型也会操纵无人机了! 只要视觉模块捕捉到启动条件,大模型这个“大脑”就会生成动作指令,接着无人机便能迅速准确地执行。 …
开源且商用 萧箫 发自 凹非寺 量子位 | 公众号 QbitAI 首个中英双语的语音对话开源大模型来了! 这几天,一篇关于语音-文本多模态大模型的论文出现在arXiv上,署名公司中出现了李开复旗下大模…
不过两者都算“半斤八两” happy 投稿 量子位 | 公众号 QbitAI 谷歌扳回一局! 在Gemini开放API不到一周的时间,港中文等机构就完成评测,联合发布了多达128页的报告,结果显示: …
从专业研究员到在校学生都适用 丰色 发自 凹非寺 量子位 | 公众号 QbitAI 多模态大模型最全综述来了! 由微软7位华人研究员撰写,足足119页—— 它从目前已经完善的和还处于最前沿的两类多模态…
视觉+音频双模态相辅相成 陈厚伦 投稿 量子位 | 公众号 QbitAI 只需一句话描述,就能在一大段视频中定位到对应片段! 比如描述“一个人一边下楼梯一边喝水”,通过视频画面和脚步声的匹配,新方法一…
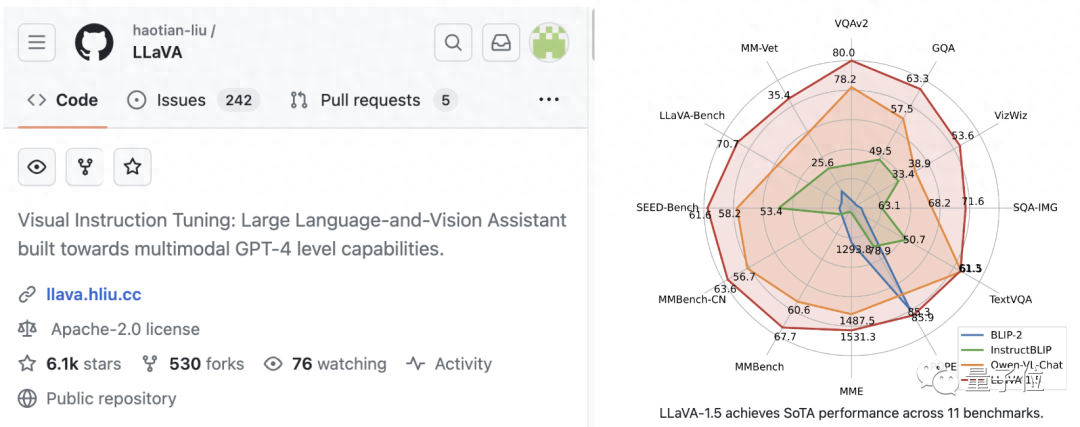
性能已达到GPT-4V的85% 克雷西 发自 凹非寺 量子位 | 公众号 QbitAI GPT-4的视觉能力还没全量放开测试,开源对手就隆重登场了。 浙大竺院的一位校友,与微软研究院等机构合作推出了新…