内容持续更新中
“未来的通用人工智能一定是多模态智能。” 作者:王咏刚,SeedV实验室创始人/CEO,创新工场AI工程院执行院长 编者按:ChatGPT/GPT-4的横空出世,已经彻底改变了NLP领域的研究态势,并…
代码已开源 转载自 沁园夏量子位 | 公众号 QbitAI 大模型“识图”能力都这么强了,为啥还老找错东西? 例如,把长得不太像的蝙蝠和拍子搞混,又或是认不出一些数据集中的稀有鱼类…… 这是因为,我们…
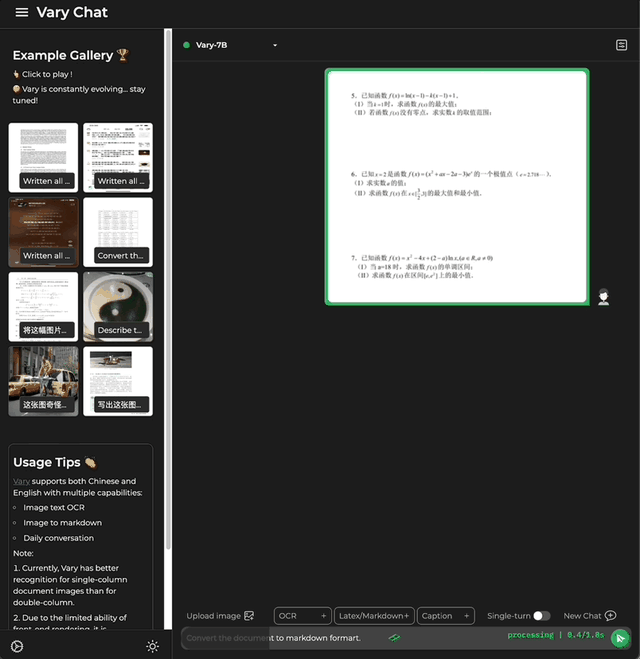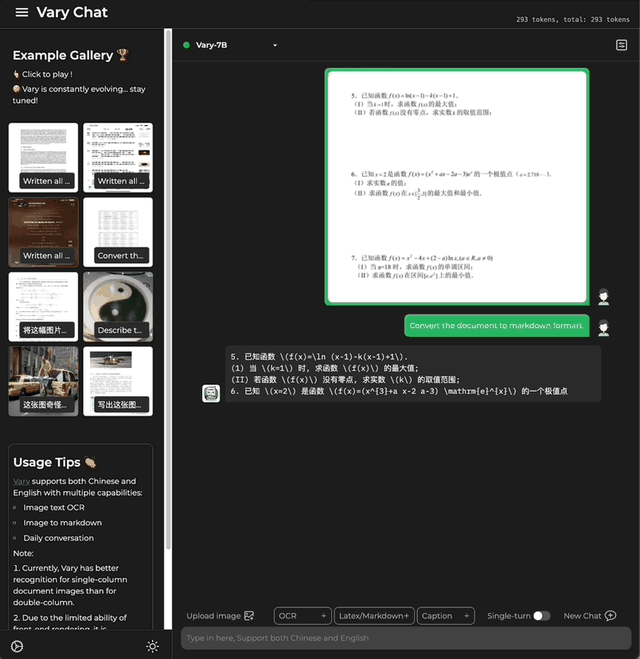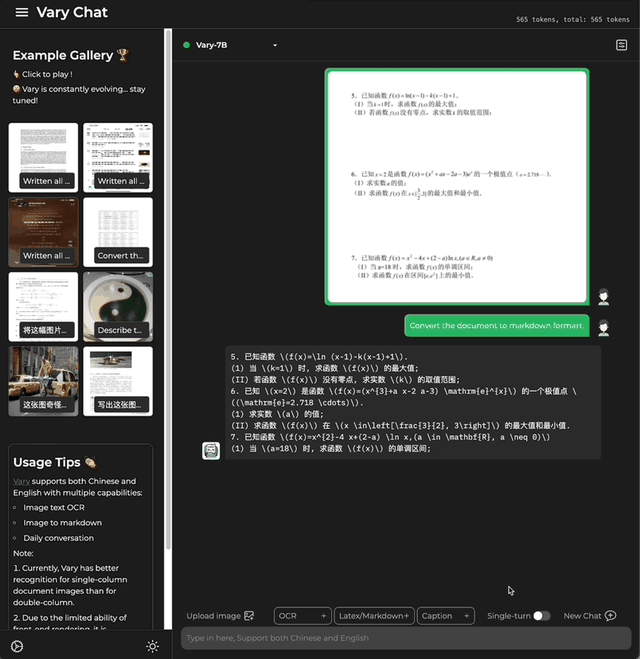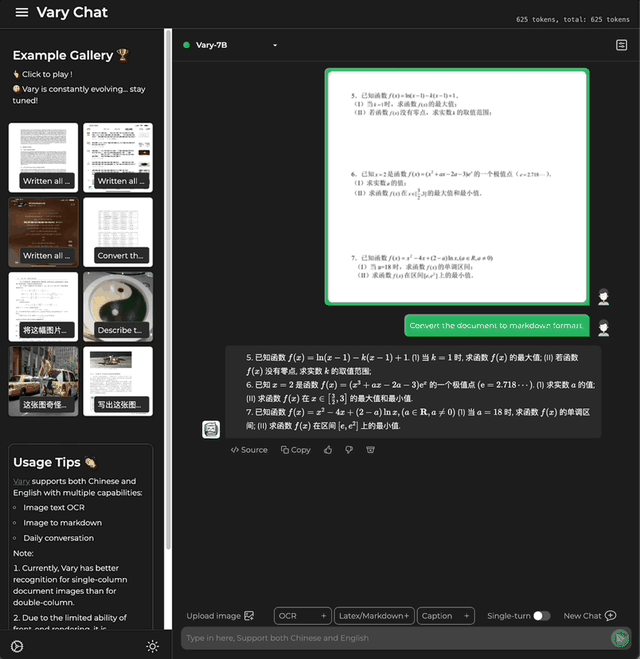
还能一键Markdown 国科大&旷视团队 投稿 量子位 | 公众号 QbitAI 想将一份文档图片转换成Markdown格式? 以往这一任务需要文本识别、布局检测和排序、公式表格处理、文本清…
离元宇宙又近一步? 梦晨 发自 凹非寺量子位 | 公众号 QbitAI Meta最新6模态大模型,让AI以更接近人类的方式理解这个世界。 比如当你听见倒水声的时候就会想到杯子,听到闹铃声会想到闹钟,现…
可即插即用 丰色 发自 凹非寺 量子位 | 公众号 QbitAI 还在用指令微调解决多模态大模型的“幻觉”问题吗? 比如下图中模型将橙色柯基错认为“红狗”,还指出周围还有几条。 现在,中科大的一项研究…
走通大模型“必经之路” 萧箫 发自 凹非寺量子位 | 公众号 QbitAI 多模态大模型,终于迎来“大一统”时刻! 从声音、文字、图像到视频,所有模态被彻底打通,如同人脑一般,实现了真正意义上的任意输…
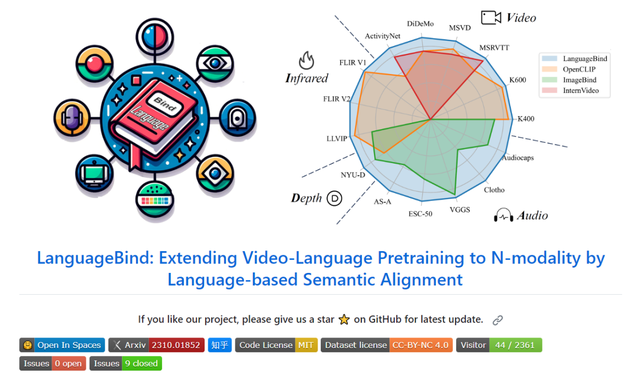
还自建首个有深度和红外的大规模多模态数据集 AI4Happiness 投稿 量子位 | 公众号 QbitAI 北大联合腾讯打造了一个多模态15边形战士! 以语言为中心,“拳打脚踢”视频、音频、深度、红…
还有开放服务平台 梦晨 发自 凹非寺量子位 | 公众号 QbitAI 大模型搞多模态,做文字、图像、音视频这几样就够了? 中科院自动化所说不: 我们还加入了3D点云和更多传感器信号。 国产大模型新成员…
3天训完130亿参数通用VLM 一个北大投稿 发送至 凹非寺 量子位 | 公众号 QbitAI 训完130亿参数通用视觉语言大模型,只需3天! 北大和中山大学团队又出招了——在最新研究中,研究团队提出…
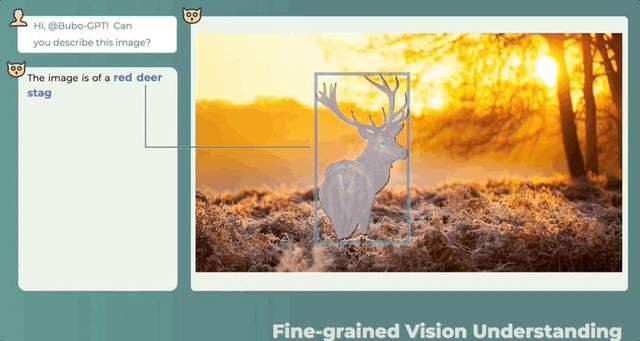
还认识班卓琴? 西风 发自 凹非寺量子位 | 公众号 QbitAI 字节大模型,BuboGPT来了。 支持文本、图像、音频三种模态,做到细粒度的多模态联合理解。 答哪指哪,什么讲了什么没讲,一目了然:…