内容持续更新中
甚至部分指标比13B的模型还要好 小炒汤圆 投稿量子位 | 公众号 QbitAI 混合专家(MoE)架构已支持多模态大模型,开发者终于不用卷参数量了! 北大联合中山大学、腾讯等机构推出的新模型MoE-…
首创基于多模态大模型的音乐理解与生成框架 腾讯PCG ARC实验室 投稿 量子位 | 公众号 QbitAI 能处理音乐的多模态大模型,终于出现了! 只见它准确分析出音乐的旋律、节奏,还有使用的乐器,甚…
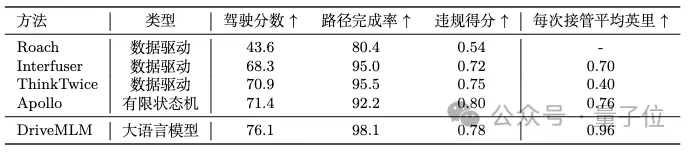
自动驾驶新解法 丰色 曹原 发自 凹非寺 量子位 | 公众号 QbitAI 用多模态大模型做自动驾驶的决策器,效果居然这么好? 来自商汤的最新自动驾驶大模型DriveMLM,直接在闭环测试最权威榜单C…
提出位置建模新方法 张傲 投稿 量子位 | 公众号 QbitAI 多模态大模型集成了检测分割模块后,抠图变得更简单了! 只需用自然语言描述需求,模型就能分分钟标注出要寻找的物体,并做出文字解释。 在其…
视觉+音频双模态相辅相成 陈厚伦 投稿 量子位 | 公众号 QbitAI 只需一句话描述,就能在一大段视频中定位到对应片段! 比如描述“一个人一边下楼梯一边喝水”,通过视频画面和脚步声的匹配,新方法一…
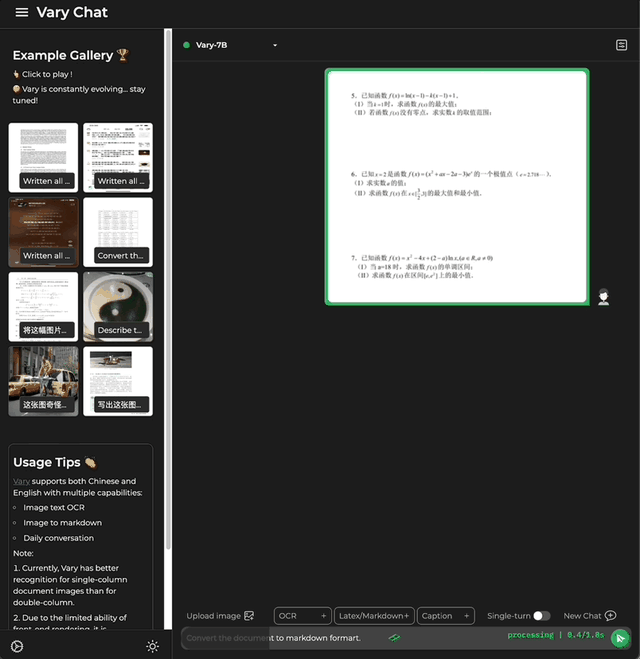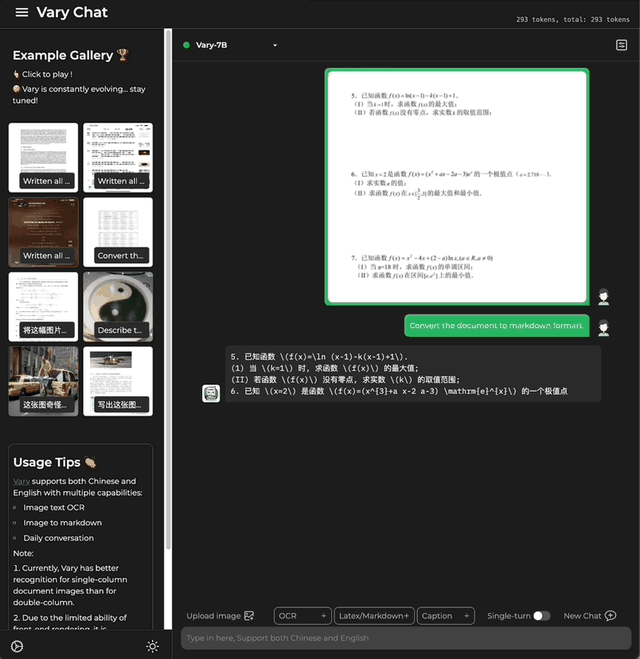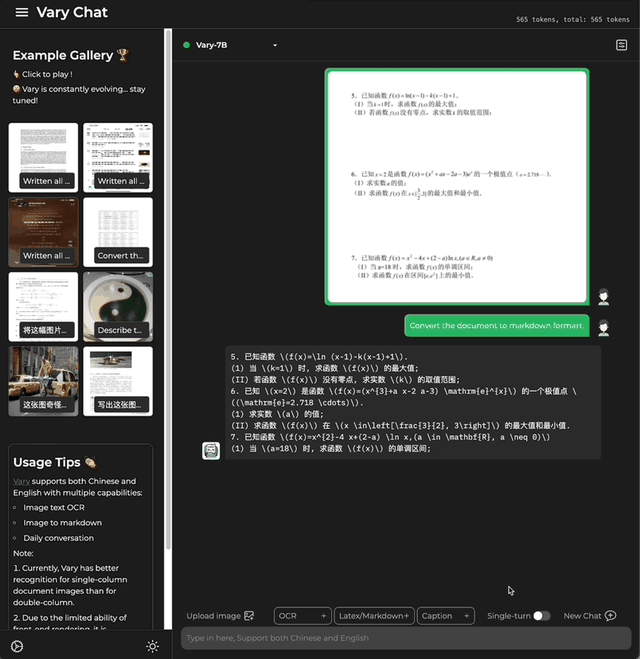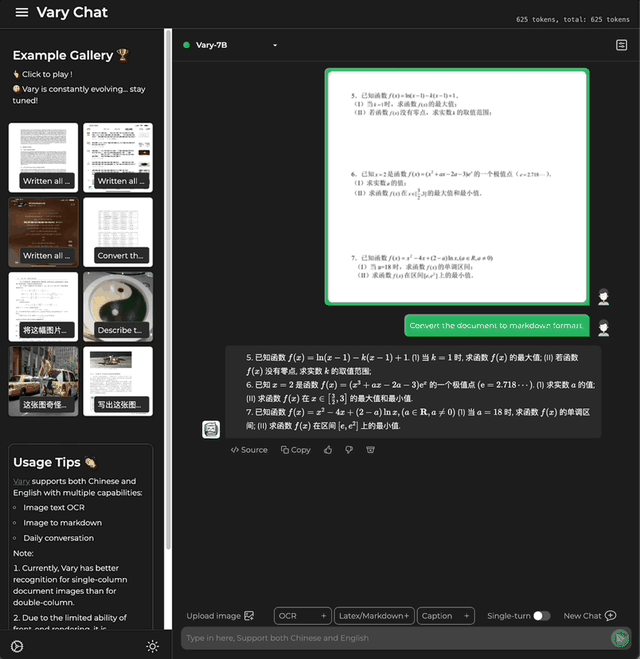
还能一键Markdown 国科大&旷视团队 投稿 量子位 | 公众号 QbitAI 想将一份文档图片转换成Markdown格式? 以往这一任务需要文本识别、布局检测和排序、公式表格处理、文本清…
不过两者都算“半斤八两” happy 投稿 量子位 | 公众号 QbitAI 谷歌扳回一局! 在Gemini开放API不到一周的时间,港中文等机构就完成评测,联合发布了多达128页的报告,结果显示: …
智能体即大脑 赵浩然 投稿 量子位 | 公众号 QbitAI 进入多模态时代,大模型也会操纵无人机了! 只要视觉模块捕捉到启动条件,大模型这个“大脑”就会生成动作指令,接着无人机便能迅速准确地执行。 …
3天训完130亿参数通用VLM 一个北大投稿 发送至 凹非寺 量子位 | 公众号 QbitAI 训完130亿参数通用视觉语言大模型,只需3天! 北大和中山大学团队又出招了——在最新研究中,研究团队提出…
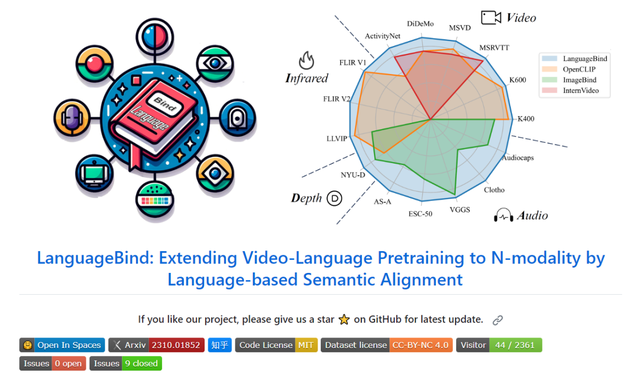
还自建首个有深度和红外的大规模多模态数据集 AI4Happiness 投稿 量子位 | 公众号 QbitAI 北大联合腾讯打造了一个多模态15边形战士! 以语言为中心,“拳打脚踢”视频、音频、深度、红…