
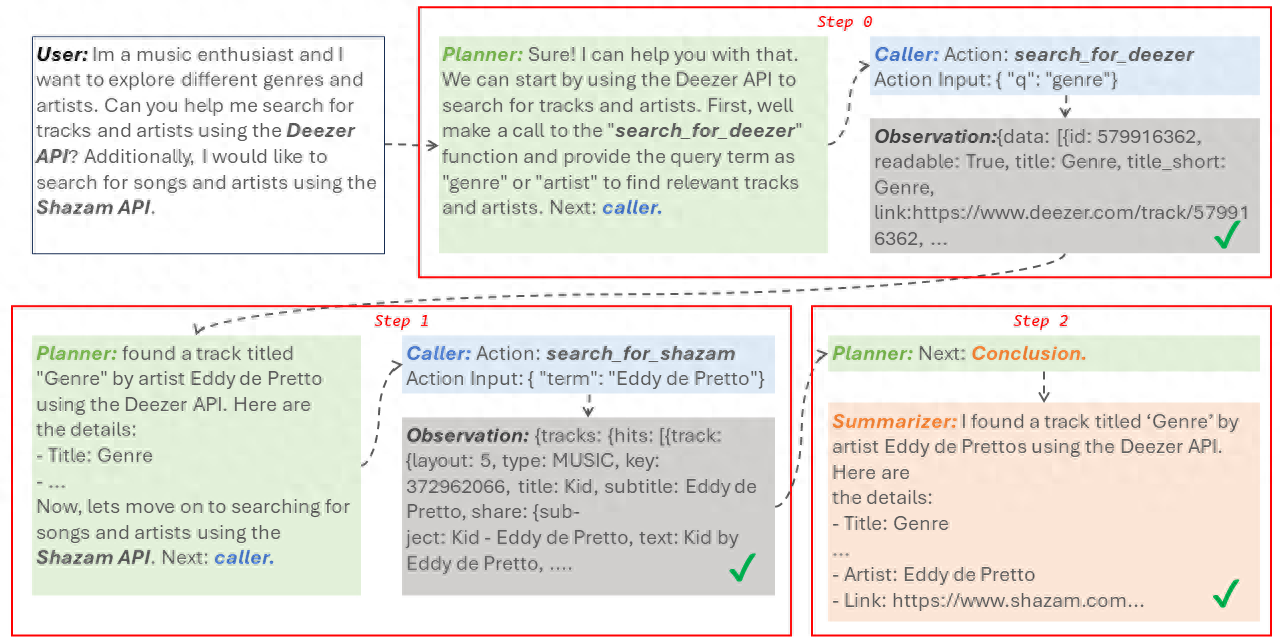
与Gemini 1.5几乎同时发布
克雷西 发自 凹非寺
量子位 | 公众号 QbitAI
上下文窗口长度达到了100万token,持平了谷歌同时推出的王炸Gemini 1.5,伯克利出品。

强大的模型,命名也是简单粗暴——没有任何额外点缀,直接就叫LargeWorldModel(LWM)。
LWM支持处理多模态信息,能在100万token中准确找到目标文本,还能一口气看完1小时的视频。
网友看了不禁表示,这种大海捞针般的测试,LWM能完成的如此出色,而且还开源,实在是令人印象深刻。

那么,LWM的表现到底有多强呢?
百万上下文窗口,可看1小时视频
在测试过程中,研究人员用多段一个多小时的视频检验了LWM的长序列理解能力,这些视频由YouTube上不同的视频片段拼接而成。
他们将这些视频输入LWM,然后针对其中的细节进行提问,涉及的片段位于整个视频的不同位置,同时研究者还将LWM与GPT-4V等模型做了对比。
结果GPT-4V是一问一个不吱声,闭源强者Gemini Pro和开源强者Video-LLaVA都给出了错误的答案,只有LWM回答对了。

在另一段视频的测试中,其他模型都说找不到有关信息,只有LWM找到了答案,而且完全正确。

不仅是理解细节,LWM也能把握视频的整体内容,做出归纳总结。

在理解的基础之上,LWM也可以结合自有知识进行推理,比如分析视频中不符合常理的地方。

Benchmark测试结果显示,LWM在MSVD-QA等三个数据集上的评分仅次于Video-LLaVA。

LWM不仅能理解长短视频,在超长文本任务上的表现同样优异。
在1百万token窗口的“插针”检索测试中,LWM取得了单针检索全绿的成绩。

多针检索时,表现也同样优异:

语言任务数据集的测试结果表明,LWM在32k到1M的窗口长度上表现不输甚至超过只有4k窗口的Llama2-7B。

除了多模态信息理解,LWM还支持图像和视频的生成,至于效果,还是直接上图感受一下吧。

那么,研究人员又是怎样训练出这样一款世界模型的呢?
循序渐进,分而治之
LMW的训练过程,大致可分为两个阶段。
第一阶段的目标是建立一个能够处理长文本序列的语言模型,以理解复杂的文档和长文本内容。
为实现这一目的,研究人员采取了渐进式的训练方式,使用总计33B Token、由图书内容组成的Books3数据集,从32k开始训练,逐步将窗口扩增至1M。

而为了增强LWM的长文本处理能力,开发者应用了RingAttention机制。
RingAttention是该团队去年提出的一种窗口扩增方式,入选了ICLR 2024。
它运用了“分而治之”的思想,将长文本分成多个块,用多个计算设备做序列并行处理,然后再进行叠加,理论上允许模型扩展到无限长的上下文。

在LWM中,RingAttention还与FlashAttention结合使用,并通过Pallas框架进行优化,从而提高性能。
在文本能力的基础上,研究人员又用模型生成了部分QA数据,针对LWM的对话能力进行了优化。

第二阶段则是将视觉信息(如图像和视频)整合到模型中,以提高对多模态数据的理解能力。
在此阶段,研究人员对LWM-Text模型进行了架构修改,以支持视觉输入。
他们使用VQGAN将图像和视频帧转换为token,并与文本结合进行训练。

这一阶段同样采用循序渐进的训练方法, LWM首先在文本-图像数据集上进行训练,然后扩展到文本-视频数据集,且视频帧数逐步增多。

在训练过程中,模型还会随机交换文本和视觉数据的顺序,以学习文本-图像生成、图像理解、文本-视频生成和视频理解等多种任务。
性能方面,研究人员在TPUv4-1024(大致相对于450块A100)上训练,批大小为8M、全精度(float32)的条件下,花费的时间如下表所示,其中1M窗口版本用了58个小时。

目前,LWM的代码、模型都已开源,其中多模态模型为Jax版本,纯文本模型有Jax和PyTorch两个版本,感兴趣的话可以到GitHub页面中了解详情。
论文地址:
https://arxiv.org/abs/2402.08268
GitHub:
https://github.com/LargeWorldModel/LWM



发评论,每天都得现金奖励!超多礼品等你来拿
登录 后,在评论区留言并审核通过后,即可获得现金奖励,奖励规则可见: 查看奖励规则