
AI领域Fellow大满贯科学家李学龙已加盟
来自央企,身份为运营商。
具体是谁?
中国电信。
所谓“不鸣则已,一鸣惊人”:
中国电信集团成立的中电信人工智能科技有限公司凭借全自研算法、精心打造的高质量数据集,发布星辰AI大模型。
其目前开源的版本在大模型知名榜单CSL上排名第五、GAOKAO排名第七、AGIEval排名第八。
什么概念?和科技公司出品的专业选手们站在了同一阵营。
现在,随着其代码和模型在Github、Gitee、HuggingFace三个平台一并可获取使用,中国电信也顺势成为央企中率先完成大模型研发和开源的选手。
加上不久之前,AI领域Fellow大满贯科学家李学龙加盟,出任电信CTO——

所以作为率先交卷大模型的央企和运营商,在大模型研发这件事上,它究竟有哪些惊艳之处?
电信大模型长什么样?
早在去年五月中旬,经过数十版模型训练与优化,中国电信就完成了百亿参数星辰AI大模型稳定版本的训练。
正式发布则是在去年7月的人工智能科技大会上,为运营商中首个。
很快,历经又一轮迭代,星辰AI大模型的千亿参数版本于11月发布。
它最大可支持96k的上下文推理,相比第一代,长文生成和理解能力提升30%。
此外,模型幻觉问题也降低了40%,并在模型量化方面取得突破——训练显存降低50%的同时,推理速度提升4.5倍。
具体来看,星辰AI大模型具备以下诸多通用能力,包括:
常识问答、写作、文本翻译润色/结构化任务、逻辑推理、数学、辅助代码生成……


模型本身则提供了近100个prompt模版任务,包括营销宣传、PPT制作、评价分析、行业分析等,方便大伙拿来就用:


在这之中,星辰AI大模型最大的亮点或者最擅长的地方就是长文写作。
根据用户提示词,它可以准确地生成结构完整、逻辑清晰的文章,平均字数超过1500字。
据统计,在电信内部,星辰AI大模型在此任务上的有效采纳率可达85.7%,和国内其他众多大模型相比,表现相当出色。
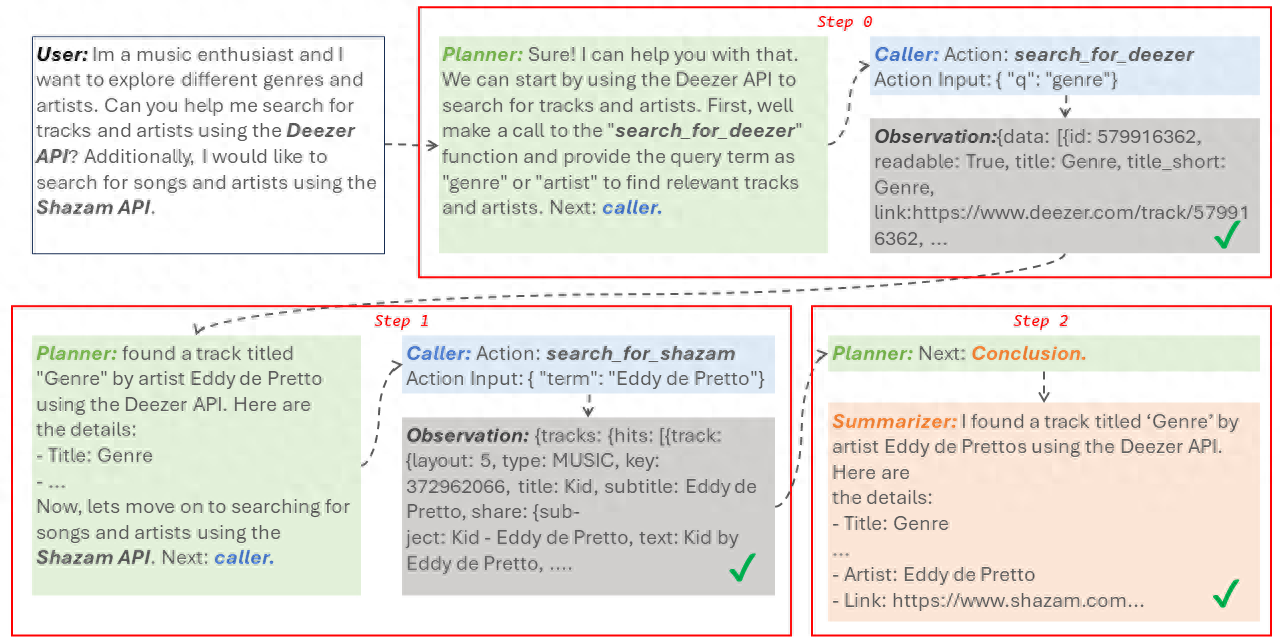
而除了长文写作这一大亮点,星辰AI大模型还具备强大的插件功能,可以解决更为复杂、多场景的任务。

例如搜索插件,用于支持各种常识问答,标注来源,使结果更为准确。

在插件的具体调用上,电信设计了非常细致的数据格式,可以使得模型深刻理解用户任务,并依照严格的流程执行推理,最终得出答案。
如果再配合上思维链技术,星辰AI大模型的能力还能更进一步。
据介绍,在中国电信企业内部以及对外企事业单位客户的业务中,星辰AI大模型已实现初步落地,在网络故障分析和客户服务业务中展现出巨大价值。
对于前者,星辰AI大模型通过对大量故障数据的学习和分析,能够迅速识别潜在问题并提供有效的解决方案,从而提高网络运维的效率和质量。
对于后者,新一代智能客服系统在接入星辰AI大模型之后,应答能力大幅提升,问题覆盖率超过95%,加上还能自动对客户服务进行准确总结,因此还能进一步优化服务流程,提高用户满意度。
对于此次开源,中国电信率先释出的则是其百亿参数版本,外推长度32k,底层代码、算法逻辑等全部公开。
大伙既可以直接调用大模型,也可以根据自身业务需求对大模型进行微调或个性化设置——支持deepspeed微调框架、int8&&int4模型量化、升腾卡训推。
或者还可以用它加载自己的知识库或数据,从而调整出更符合自身业务需求、更加个性化的理想结果。
具体来看,和前面介绍的还不同,电信将星辰AI大模型能力分门别类,此次一共开源的是5个细分大模型。
除了最基础的星辰语义大模型,还包括:
- 星辰语音大模型 ,它具备关键词检测、超自然语音合成、语音识别、语音翻译、声音匿名、AI 作曲和语音生成七大类算法能力,可用于音频会议纪要整理、智能语音机器人等场景;

- 星辰多模态大模型,支持文生图、图生图,可用于内容创作、广告营销等;

- 启明网络大模型,专攻网络运营,侧重云网运营领域专业知识查询;
- 星辰经分大模型,主攻数据分析和报告生成。
可以说相当全面了。
算法纯自研,核心优势在数据
有点惊喜有点意外,作为一家运营商,电信在大模型研发这件技术活上拿出态度,走了纯自研方式:
背后搭建了一支800人的研发团队,硕博占比超54.9%的那种。
他们在模型结构、数据预处理、模型预训练以及人类偏好对齐、降低幻觉等方面都进行了优化,注入了电信自己的“灵魂”。
具体来看,在模型结构设计上,团队采用解码器架构(decoder-only)并改进旋转位置编码(RoPE),再结合自适应插值的NTK-aware + LogN算法,大幅提高了模型的外推能力,使其支持超长上下文(96k)理解。
在模型训练上,为了保证稳定性,团队又使用了Embedding LayerNorm算法,在嵌入层添加额外的RMSNorm层,并在每个Transformer子层前加入RMSNorm层。
为了提升训练和推理速度,他们又采用了SwiGLU激活函数替代传统GELU激活函数的方式,将隐藏层大小设计为8/3d而非4d。
再通过将RoPE与FlashAttention-V2相结合,模型的训练速度进一步提高了20%以上。
在微调阶段,团队的做法则是在embedding层加入噪声扰动来缓解过拟合,进一步提升模型问答质量。
人类指令对齐上也下了不少功夫,经过一系列bge向量化+聚类以及人类标注的方式,团队得到完整、全面的基于人类偏好的排序数据。
然后又多次尝试PPO、RRHF和DPO在内的人类偏好排序数据训练策略,最终选择DPO进行训练,实现人类偏好对齐,由此提升模型生成答案的安全性和规范性。
最后,在大模型幻觉问题上,中国电信研发团队也给出了一套完整的解决方案:包括关键信息注意力增强技术、多轮知识记忆和强化技术、知识图谱强化技术以及知识溯源,最终将大模型幻觉降低了40%。

——技术上的努力说了这么多,在造大模型这件事上,电信到底有哪些优势呢?
最为核心的就是数据。
数据的重要性对于大模型的性能不言而喻,而当下,中文互联网数据由于数据孤岛、AI生成污染等问题存在获取困难、质量堪忧等情况。
在此,电信除了大量来自百科、书籍、司法、医药等维度的通用数据,也凭借自身业务积累了不少行业数据。
这使得电信大模型的中文训练数据超过25TB,中文总token量超8万亿。
经过Knesey-Ney技术过滤、Minihash+Jaccard排重,以及几百人专业标注团队的人工标注,这批数据化为非常高质量的数据集,为星辰AI大模型算法训练打下坚实基础。

(值得一提的是,电信也将开源其中大部分数据,值得大伙期待一波。)
数据集有了,其次,算力也不缺:
对于大模型训练所需的极大算力需求,中国电信通过“2+31”天翼云布局基础,构建了全国四级超大算力底座来满足。
简单来说就是来自集团的2大核心算力集群(包含近万台GPU)与31个省级算力集群(同样近万台GPU)进行云边端协同,实现算力资源全国统筹调度管理,AI能力一键下发,多个大模型进行同时训练也可满足。
最后,再加上前面所讲的一系列核心算法自研和优化,电信凭“数算法”三大强力后盾,甩出了星辰大模型这份成绩单。

现在,更是将它豪气开源,和专业选手一起,敢于直接交给公众来检验。
那么,问题来了——
为什么能做到央企中第一个发布大模型?
首先,是态度上重视。
在大模型和AI技术上,中国电信有基础有布局。
除了星辰AI大模型,在去年11月举办的数字科技生态大会上电信还发布了12个行业大模型,并推出“星辰MaaS生态服务平台”,实现定制化服务。
以及可开箱即用的大模型生产应用流水线产品“慧聚”,它预置多种基础大模型、开发环境、数据训练工具等,使得电信不仅自己生产大模型,还提供能力帮其他企业开发大模型。
而这一切,基于的是电信已历经10年的AI能力建设。

在软件算法领域,中国电信的人脸识别、动作检测、对象跟踪检测等多项技术斩获世界大奖,数字人技术所支撑的智能客服产品也在国际赛事DCASE2023 task-A赛道中获得季军,此外还与华为联合发布了AI高性能推理框架UniStream。
这无比体现着中国电信扎实的AI基础实力。
其次,有人才有大牛。
如前文介绍,为了搭星辰AI大模型,中国电信快速组建了一支近800人的研发团队,成员来自国内外顶尖高校,如清华、北大、斯坦福和哥伦比亚等,平均年龄31.79岁。
其中纯技术人员占比75%,硕博占比超54.9%,这波人才帮助电信在对内对外业务中取代外部算法能力,实现核心算法能力自主可控。
在广纳基础人才之外,电信也坐拥一批大牛,其中包括去年年底全职加盟中国电信担任CTO以及首席科学家的李学龙。
作为AI领域Fellow大满贯选手、“多模态认知计算”的提出者,他将带领电信人工智能研究院,继续开展基础、前沿研究。
最后,我们了解到,其实不止于AI和大模型,中国电信在很多技术上都进行了投入,并且也取得了同行优势。
例如量子通信,中国电信不久前发布了具备“量子优越性”能力的“天衍”量子计算云平台,此前还开通了国内规模最大、用户最多、应用最全的量子保密通信城域网,并主导制定了中央企业第一牵头立项的7项量子通信行业标准(含团标)中的5项。
再例如在新一代信息通信技术上,中国电信实现“手机直连卫星”全面商用,发布了全球首个支持消费级5G终端直连卫星双向语音和短信的运营级产品。
可以看出,中国电信虽为传统运营商,但在技术上一贯都很重视,并且在其中的投入可能比我们想象得还要深。
因此,对于本段提出的问题:
为什么中国电信能做到央企中第一个发布大模型?
答案也就情理之中了。

发评论,每天都得现金奖励!超多礼品等你来拿
登录 后,在评论区留言并审核通过后,即可获得现金奖励,奖励规则可见: 查看奖励规则