
未知物体分割也能迎刃而解
张浩 投稿
量子位 | 公众号 QbitAI
ICCV论文收录名单近日「开奖」,其中就包括这个港科大一作的图像分割模型!
它能以更低的训练成本实现更好的效果,哪怕遇到未知物体也能迎刃而解。
此外据作者介绍,它还是第一个拥有基于box prompts的分割能力的AI模型,比Meta的SAM还要早实现。


这篇论文第一版预印本的发布时间是今年的3月14日(北京时间15日),比SAM早了20多天。
那么,这个图像分割模型,究竟效果如何,又是如何做到的呢?
(以下内容由投稿者提供)
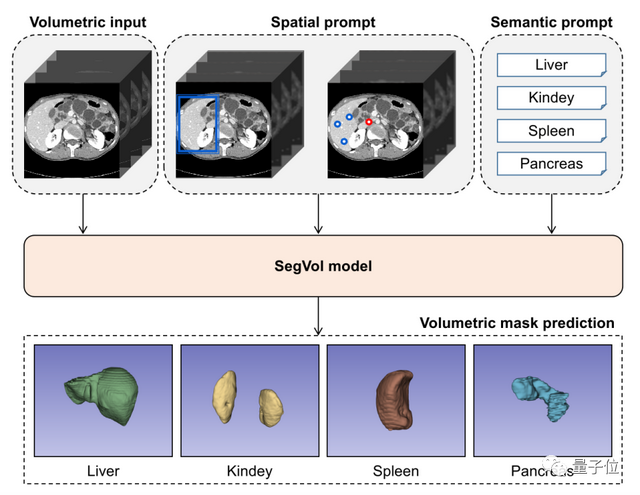
下图展示了这个名为OpenSeeD的模型的输出效果:

它既可以做经典的实例、语义以及全景分割,又可以分割出从未见过的物体类别,还可以基于检测框分割出从未见过的物体并给出正确的类别。
工作原理
OpenSeeD是一个简单而有效的开放词表图像分割的框架,也可以理解为MaskDINO扩展到开放词表的版本。
如下图所示,过去已经有不少工作结合大量的图像文本对实现开词表检测或者分割,而OpenSeeD是第一个把物体检测数据和全景分割数据结合在一起联合训练的工作,并且证明是可行有效的,填补了这一领域的空白。

除此以外,为了扩展语义的丰富程度,研究团队引入O365(365类)检测数据和COCO分割(133类)一起训练(不同于MaskDINO使用O365预训练)。
由于使用了不同的数据集,研究团队需要解决了二者之间的数据和任务的差异,以便两个任务和词表兼容。
整体上,OpenSeeD的工作原理如下图所示,两种差异也是通过这一方式解决的:

图中左半部分完成的是通用场景分割。
为了解决基础模型的任务差别(O365只有前景,而COCO有前景和背景),研究团队把前景和背景的预测进行解耦。

右半部分是条件预测部分,可以通过GT box预测图像遮罩。
在这一部分中,团队通过为O365打标签为了解决数据差异问题。
最终,该团队的方法在多个开放词表任务上取得了与当前最佳方法x-decoder相当甚至更好的效果,相比x-decoder用了4M人工标注的图像描述数据,OpenSeeD只用了0.57M的检测数据。
另外,研究团队还发现,即使只用5k的O365数据,也可以在开放词表任务上达到类似的效果。
这说明OpenSeeD需要的是丰富的视觉概念(种类数),而不一定是很大的数据量(个体数)。
低成本,高效果
OpenSeeD作为一个强大的开集分割方法,可以分割出大量从未见过的物体,在各项开集和闭集指标上都取得了最佳成绩。
而且通过引入O365检测任务来提升开集语义能力,OpenSeeD的训练成本也相对其他开集方法更低。
下表展示了OpenSeeD的测试结果:

通过较少的检测数据,研究团队发现在多个零训练样本分割任务上达到或超越了现有最佳方法X-Decoder,GLIPv2等,尤其在SeginW任务(大量陌生类别)上取得了远超X-Decoder的效果。

除此以外,当团队微调到其他数据集时,OpenSeeD都表现出了远超参照标准的性能。
在COCO和ADE20K的全景分割以及ADE20K和Cityscapes的实例分割上,OpenSeeD的性能也与现有最佳模型相当。

论文地址:
https://arxiv.org/abs/2303.08131


发评论,每天都得现金奖励!超多礼品等你来拿
登录 后,在评论区留言并审核通过后,即可获得现金奖励,奖励规则可见: 查看奖励规则