
ChatGPT稳夺第一
转载自 智源研究院
量子位 | 公众号 QbitAI
2023 年高考成绩陆续出炉,我们也来看看各大语言模型的“高考成绩”如何?

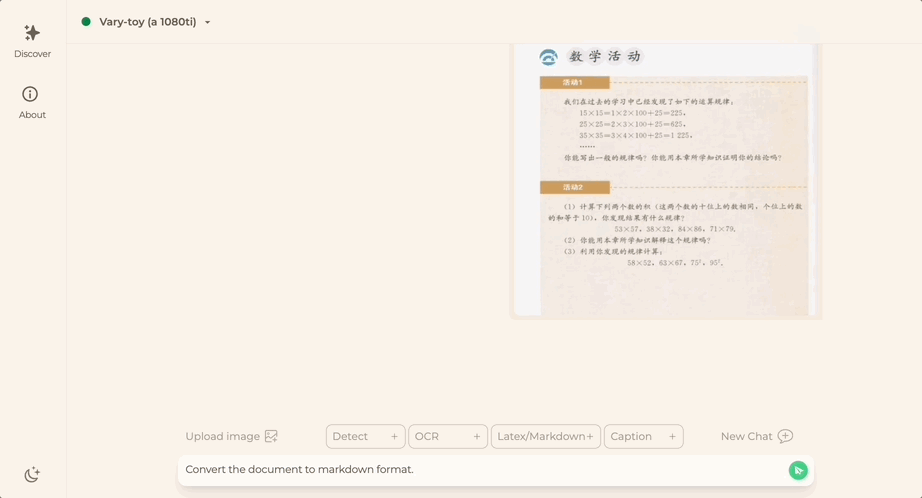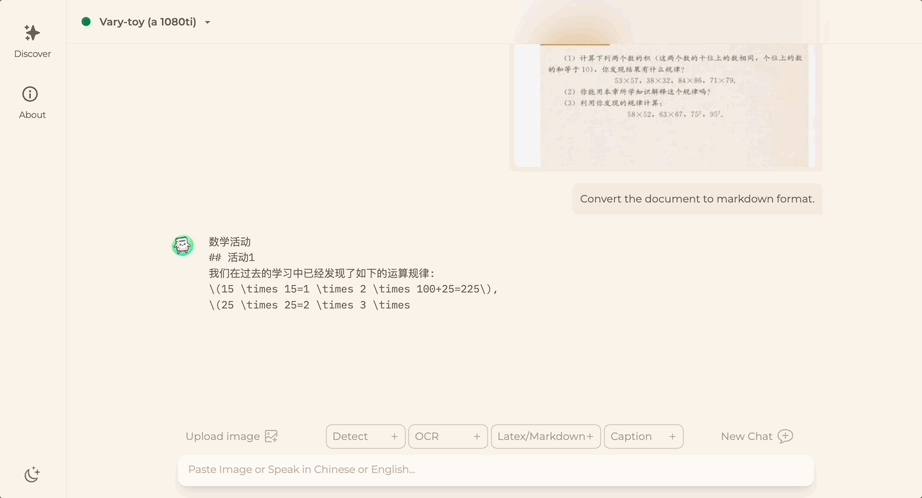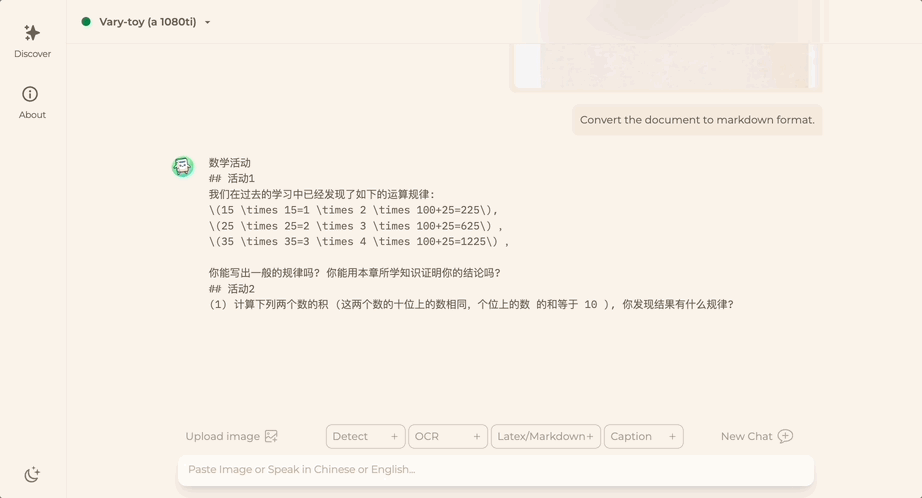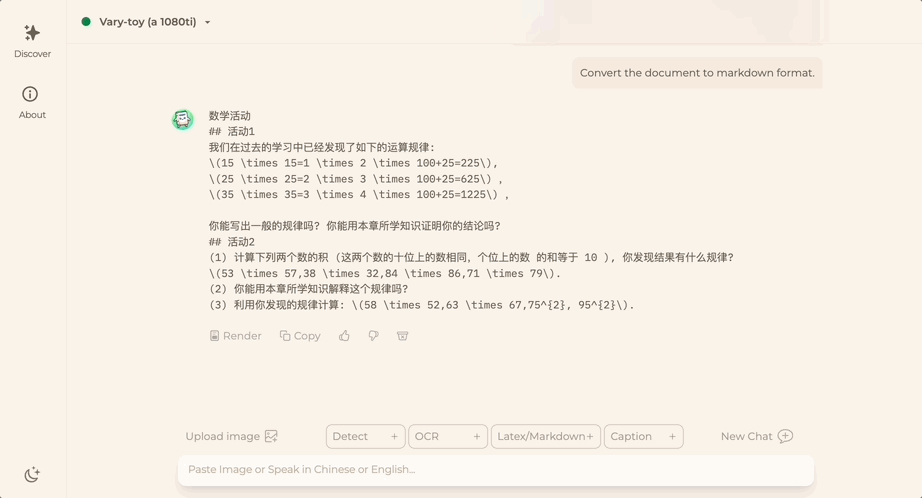
FlagEval 大模型评测团队从 2023年高考考卷中整理了 147 道客观题(其中语文 20道,英语 44道,历史 31道,数学 9道,物理 8道,政治 21道,生物 14道)形成 Gaokao2023 V1.0 评测集。
排除特殊符号等因素之后,通过 5-shot 方式对参数量相近的开源大语言模型进行评测,如悟道·天鹰 AquilaChat、Alpaca、Chinese-Alpaca、StableLM-tuned-alpha、MOSS、BELLE、ChatGLM等。
鉴于 2023 高考题 6 月初才发布,尚未进入模型训练数据集,此次测试结果能较为直接地反映模型的知识运用能力。
ChatGPT 毫无悬念得分最高,GPT-4 和 GPT-3.5-turbo 正确率分别为 60.4%、42.5%。
悟道·天鹰 AquilaChat-7B 在国内外参数量相近的SFT开源模型中表现亮眼,以 37.2% 正确率的综合成绩位居首位,接近 GPT-3.5-turbo 水平。
而 ChatGLM2-6B、Chinese-Alpaca 紧随其后,正确率分别为 25.5%、24.7%。

经SFT微调的模型与基础模型在能力侧重点上具有明显差异。
公平起见,仅对比经SFT微调后的语言模型。

评测方式解释:
本次评测采用 5-shot 的 In-context 形式 prompt 作为输入,即在 Prompt 中给给出 5 个示例和答案作为 Context,最后附上一道评测题目,要求模型选择输出【A/B/C/D】中的正确选项,考察模型的 In-Context(上下文)学习能力和知识量。总成绩(TOTAL)为每个模型的 7 个学科成绩算数平均值。
从学科成绩中,还有几点有趣的发现:
- AquilaChat 学科知识非常均衡,没有明显的短板,并且生物、物理成绩突出,正确率分别达到 50%、62.5%;
- 相比英语成绩,所有模型的语文成绩普遍不高,AquilaChat 与 Chinese-Alpaca 以 15% 正确率并列第一,ChatGPT 的正确率也仅有 10% 。说明大模型在学习中文知识时难度较大,这对后续中英双语大模型训练提出了挑战。
这次针对2023高考的能力评测,主要对国内外7B量级开源大模型进行对比。7B 量级作为当前主流模型,因部署性价比高,广受产业欢迎。
“巨无霸”ChatGPT作为标志参照项,在“高考2023评测”等能力对比中依然“一览众山小”。
考虑到其在模型参数量、训练数据量方面的巨大差异,以 AquilaChat-7B 为代表的 7B 量级开源模型,依然实力不容小觑、未来可期!
目前尚未有公开信息
FlagEval 大语言模型评测榜单上新
Gaokao2023 V1.0(高考评测结果)已更新至 FlagEval 大语言模型评测榜单。我们将持续扩充题库能力,提升对模型评测结果的深入分析能力。
欢迎大模型研究团队评测申请:
flageval.baai.ac.cn
智源FlagEval大模型开放评测平台,创新构建了“能力-任务-指标”三维评测框架,划定了大语言模型的 30+ 能力维度,在任务维度集成了 20+ 个主客观评测数据集,不仅涵盖了知名的公开数据集 HellaSwag、MMLU、C-Eval 等,还增加了智源自建的主观评测数据集 Chinese Linguistics & Cognition Challenge (CLCC) ,北京大学与闽江学院共建的词汇级别语义关系判断、句子级别语义关系判断、多义词理解、修辞手法判断评测数据集。更多维度的评测数据集也在陆续集成中。

在最新 SFT 模型评测榜单中,AquilaChat 在“主观+客观”评测中排名第一。
据悉,悟道 · 天鹰 Aquila-7B基座模型及AquilaChat 对话模型最新版本权重已经更新至开源仓库,相比 6 月 9 日初始版本性能在常识推理、代码生成等维度,有了较高提升。目前可通过 FlagAI 开源项目或 FlagOpen 模型仓库下载权重。
GitHub:
https://github.com/FlagAI-Open/FlagAI/tree/master/examples/Aquila
模型仓库:
https://model.baai.ac.cn/models


发评论,每天都得现金奖励!超多礼品等你来拿
登录 后,在评论区留言并审核通过后,即可获得现金奖励,奖励规则可见: 查看奖励规则