
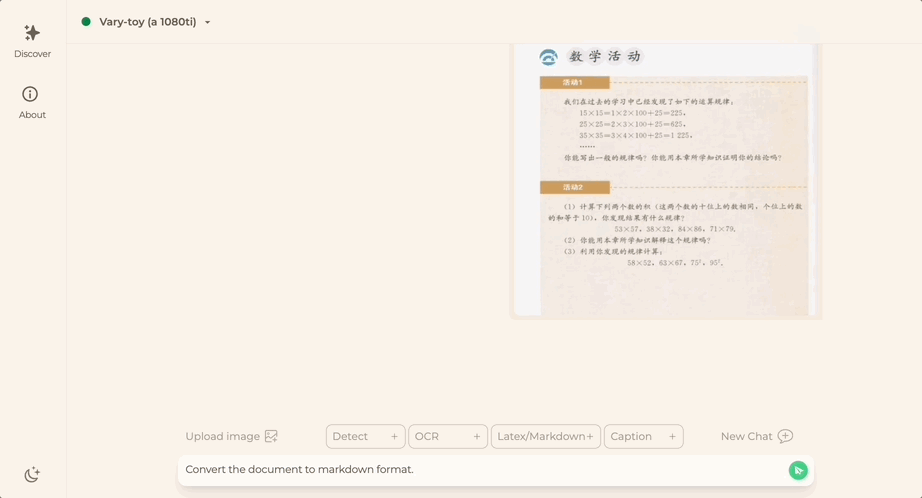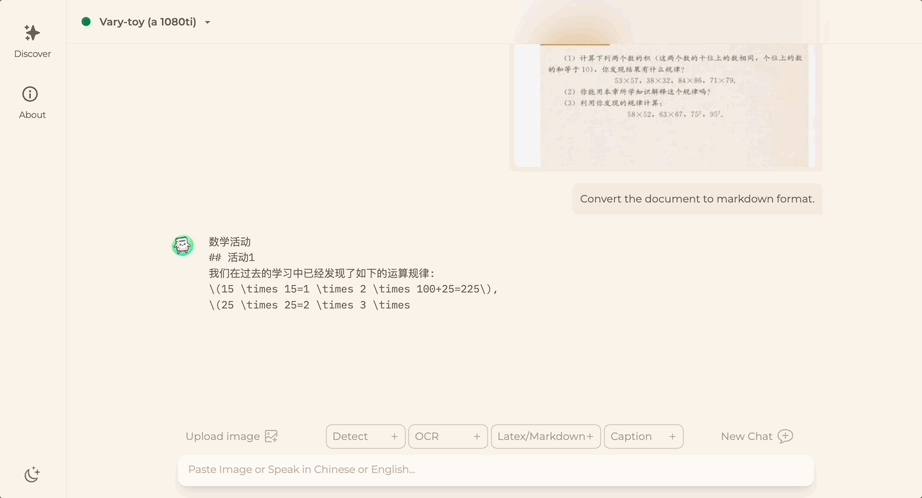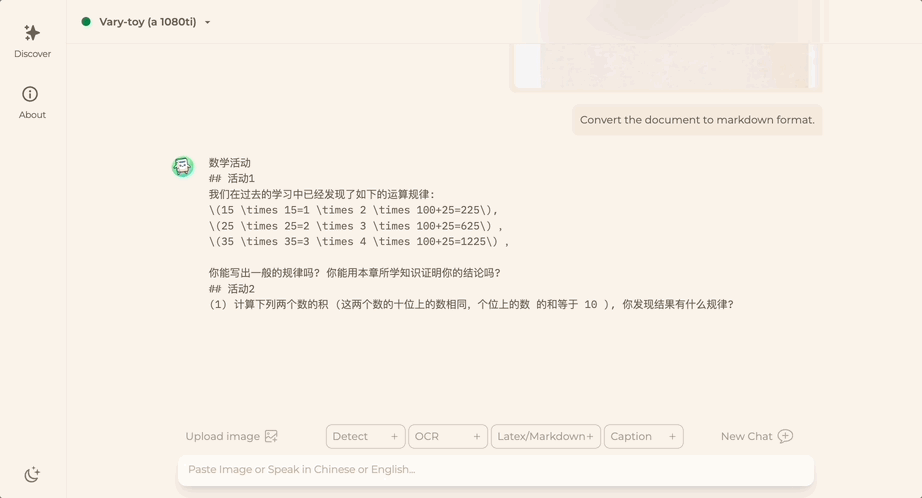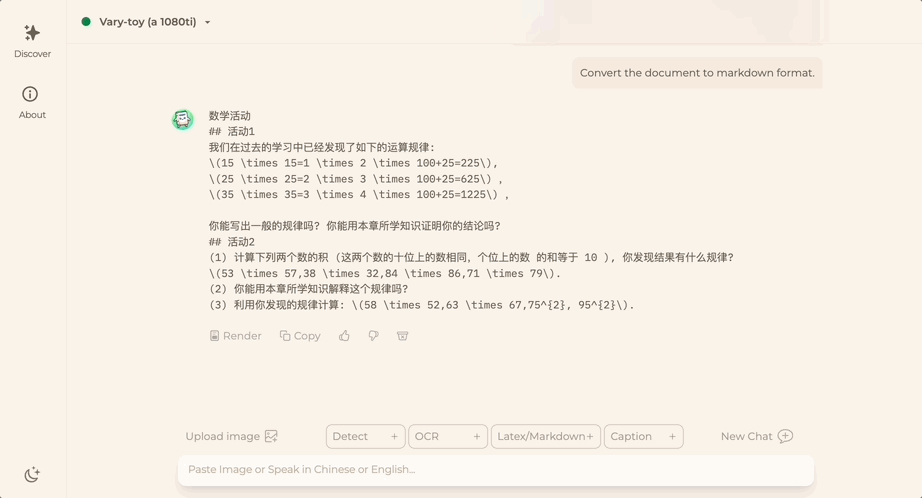
主打高灵活性、可控性
西风 发自 凹非寺
量子位 | 公众号 QbitAI
Direct-a-Video,成功解耦AI生成视频中物体运动和摄像机运动,让灵活性和可控性大大增强!
不信,来欣赏一波作品。
短视频中的镜头移动方向全凭导演指令,水平(X轴)、垂直(Y轴)、变焦必须精准:

AI导演还上演了一出炫技,镜头移动方向混合水平、垂直:

混合水平、变焦运动效果也可以

此外,导演还要求视频中的每个“演员”都能按照绘制的框框运动:

达到镜头移动和演员运动合一的效果。
比如,大熊原地太空漫步,镜头水平和垂直移动实现整体视频运动效果:

当然大熊的位置也可以通过绘制带箭头的框框,从一个地方移动到另一个地方:

甚至还能同时分别控制多个“演员”的移动路径:

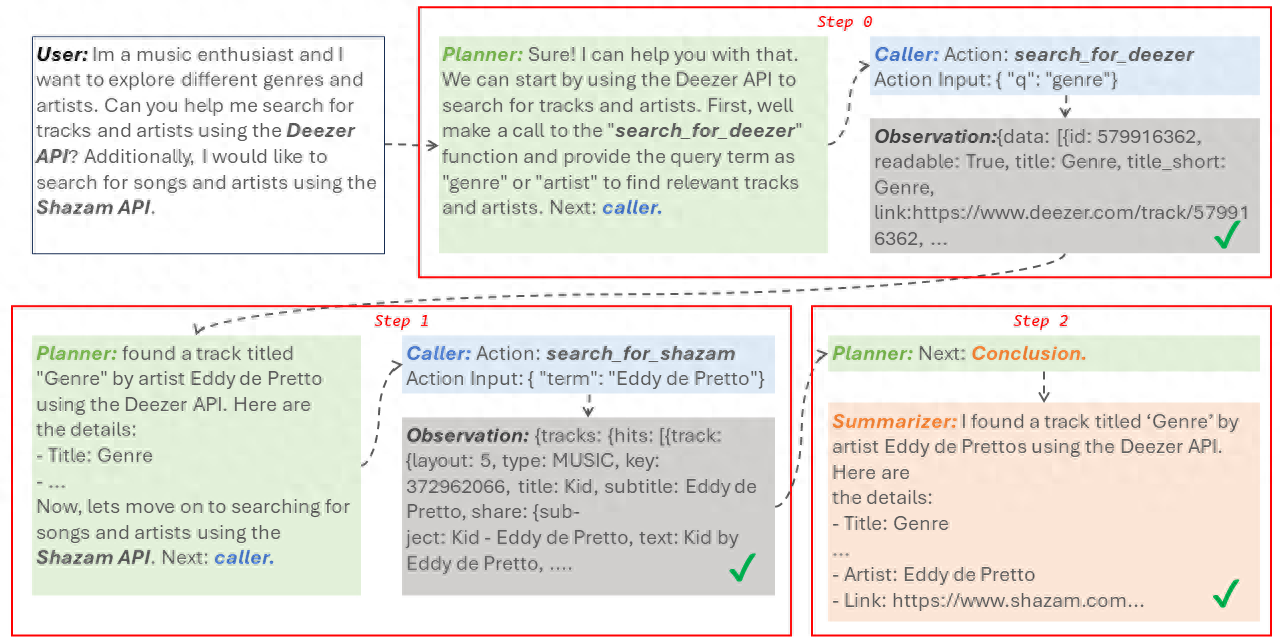
这就是香港城市大学、快手科技、天津大学研究团队共同提出的Direct-a-Video文本-视频生成框架的效果展示。

怎么做到的?
具体来说,Direct-a-Video分为两个板块——
在训练阶段,学习相机移动控制;在推理阶段,实现物体运动控制。
在实现相机移动控制时,研究人员采用了预训练的ZeroScope文本到视频模型作为基础模型,并引入新的可训练时间自注意力层(相机模块),将由Fourier编码和MLP映射的平移和变焦参数嵌入注入其中。
训练策略是在有限数据上,使用数据增广的自监督训练方式学习相机模块,无需人工运动标注。
其中数据增广通俗来讲,就是添加已有数据的略微修改版,或从现有数据中创建新的合成数据来增加数据量:
经过自监督训练后,该模块可以解析相机运动参数实现定量控制。
实现物体运动控制时,不需要额外的数据集和训练,只需用户简单绘制首末帧框和中间轨迹即可定义物体运动。
简单来说,直接在推理时采用基于像素的自注意力增强和抑制,分时阶段调控每帧内各对象的自注意力分布,从而使对象生成到用户通过一系列框指定的位置,实现物体运动轨迹控制。
值得一提的是,相机移动控制和物体运动控制互相独立,允许单独或联合控制。
Direct-a-Video效果如何?
研究人员将Direct-a-Video与多基准对比验证了该方法的有效性。
相机移动控制评估
Direct-a-Video与AnimateDiff和VideoComposer对比结果如下:
Direct-a-Video在生成质量、相机移动控制精度上均优于基线:
物体运动控制评估
Direct-a-Video与VideoComposer和Peekaboo对比,验证了本方法在多物体及运动场景下的控制能力。
在生成质量和物体运动控制精度上优于VideoComposer:
网友看到效果直呼因锤斯汀:
除Runway外,又多了一种新选择。
PS:
Runway Gen-2“运动笔刷”(Motion Brush),涂哪儿动哪儿,同样可调整参数控制运动方向:
参考链接:
[1]https://x.com/dreamingtulpa/status/1756246867711561897?s=20
[2]https://arxiv.org/abs/2402.03162


发评论,每天都得现金奖励!超多礼品等你来拿
登录 后,在评论区留言并审核通过后,即可获得现金奖励,奖励规则可见: 查看奖励规则