
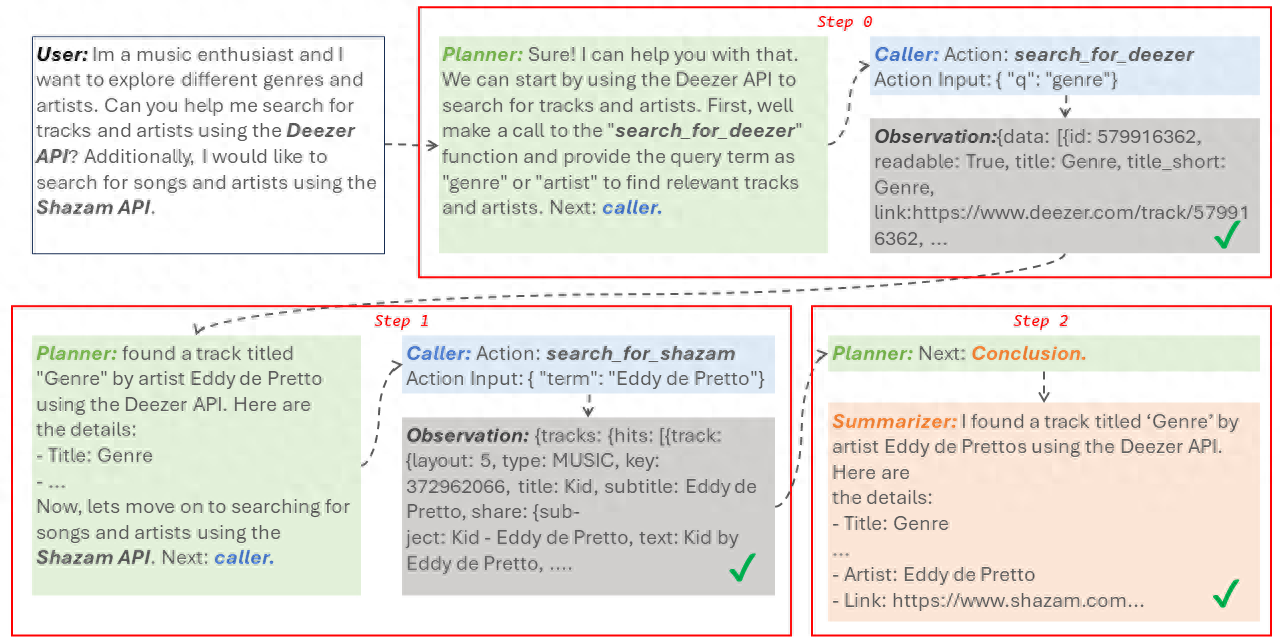
AI画文字终于能画对了
梦晨 发自 凹非寺
量子位 | 公众号 QbitAI
开源AI绘画扛把子,Stable Diffusion背后公司StabilityAI再放大招!
全新开源模型DeepFloyd IF,一下获星2千+并登上GitHub热门榜。

DeepFloyd IF不光图像质量是照片级的,还解决了文生图的两大难题:
准确绘制文字。(霓虹灯招牌上写着xxx)

以及准确理解空间关系。(一只猫照镜子看见狮子的倒影)

网友表示,这可是个大事,之前想让Midjourney v5在霓虹灯招牌上写个字AI都是瞎划拉两笔,对于镜子理解的也不对。

使用DeepFloyd IF,可以把指定文字巧妙放置在画面中任何地方。
霓虹灯招牌、街头涂鸦、服饰、手绘插画,文字都会以合适的字体、风格、排版出现在合理的地方。

这意味着,AI直出商品渲染图、海报等实用工作流程又打通一环。
还在视频特效上开辟了新方向。

目前DeepFloyd IF以非商用许可开源,不过团队解释这是暂时的,获得足够的用户反馈后将转向更宽松的协议。

有需求的小伙伴可以抓紧反馈起来了。
像素级图像生成
DeepFloyd IF仍然基于扩散模型,但与之前的Stable Diffusion相比有两大不同。
负责理解文字的部分从OpenAI的CLIP换成了谷歌T5-XXL,结合超分辨率模块中额外的注意力层,获得更准确的文本理解。
负责生成图像的部分从潜扩散模型换成了像素级扩散模型。
也就是扩散过程不再作用于表示图像编码的潜空间,而是直接作用于像素。
官方还提供了一组DeepFloyd IF与其他AI绘画模型的直观对比。
可以看出,使用T5做文本理解的谷歌Parti和英伟达eDiff-1也都可以准确绘制文字,AI不会写字这事就是CLIP的锅。
不过英伟达eDiff-1不开源,谷歌的几个模型更是连个Demo都不给,DeepFloyd IF就成了更实际的选择。
具体生成图像上DeepFloyd IF与之前模型一致,语言模型理解文本后先生成64×64分辨率的小图,再经过不同层次的扩散模型和超分辨率模型放大。
在这种架构上,通过把指定图像缩小回64×64再使用新的提示词重新执行扩散,也实现以图生图并调整风格、内容和细节。
并且不需要对模型做微调就可直接实现。
另外,DeepFloyd IF的优势还在于,IF-4.3B基础模型是目前扩散模型中U-Net部分有效参数是最多的。
在实验中,IF-4.3B取得了最好的FID分数,并达到SOTA(FID越低代表图像质量越高、多样性越好)。
谁是DeepFloyd
DeepFloyd AI Research是StabilityAI旗下的独立研发团队,深受摇滚乐队平克弗洛伊德影响,自称为一只“研发乐队”。
主要成员只有4人,从姓氏来看均为东欧背景。
这次除了开源代码外,团队在HuggingFace上还提供了DeepFloyd IF模型的在线试玩。
我们也试了试,很可惜的是目前对中文还不太支持。
原因可能是其训练数据集LAION-A里面中文内容不多,不过既然开源了,相信在中文数据集上训练好的变体也不会太晚出现。
One More Thing
DeepFloyd IF并不是Stability AI昨晚在开源上的唯一动作
语言模型方面,他们也推出了首个开源并引入RLHF技术的聊天机器人StableVicuna,基于小羊驼Vicuna-13B模型实现。
目前代码和模型权重已开放下载。
完整的桌面和移动界面也即将发布。
Deepfloyd IF在线试玩:
https://huggingface.co/spaces/DeepFloyd/IF
代码:
https://github.com/deep-floyd/IF
StableVicuna在线试玩:
https://huggingface.co/spaces/CarperAI/StableVicuna
权重下载:
https://huggingface.co/CarperAI/stable-vicuna-13b-delta
参考链接:
[1]https://deepfloyd.ai/deepfloyd-if
[2]https://stability.ai/blog/deepfloyd-if-text-to-image-model
[3]https://stability.ai/blog/stablevicuna-open-source-rlhf-chatbot
[4]https://stable-diffusion-art.com/how-stable-diffusion-work/



发评论,每天都得现金奖励!超多礼品等你来拿
登录 后,在评论区留言并审核通过后,即可获得现金奖励,奖励规则可见: 查看奖励规则