内容持续更新中
ChatGPT的SFT+RLHF都不是必要的??? 梦晨 发自 凹非寺量子位 | 公众号 QbitAI 要搞大模型AI助手,像ChatGPT一样对齐微调已经是行业标准做法,通常分为SFT+RLHF两步…
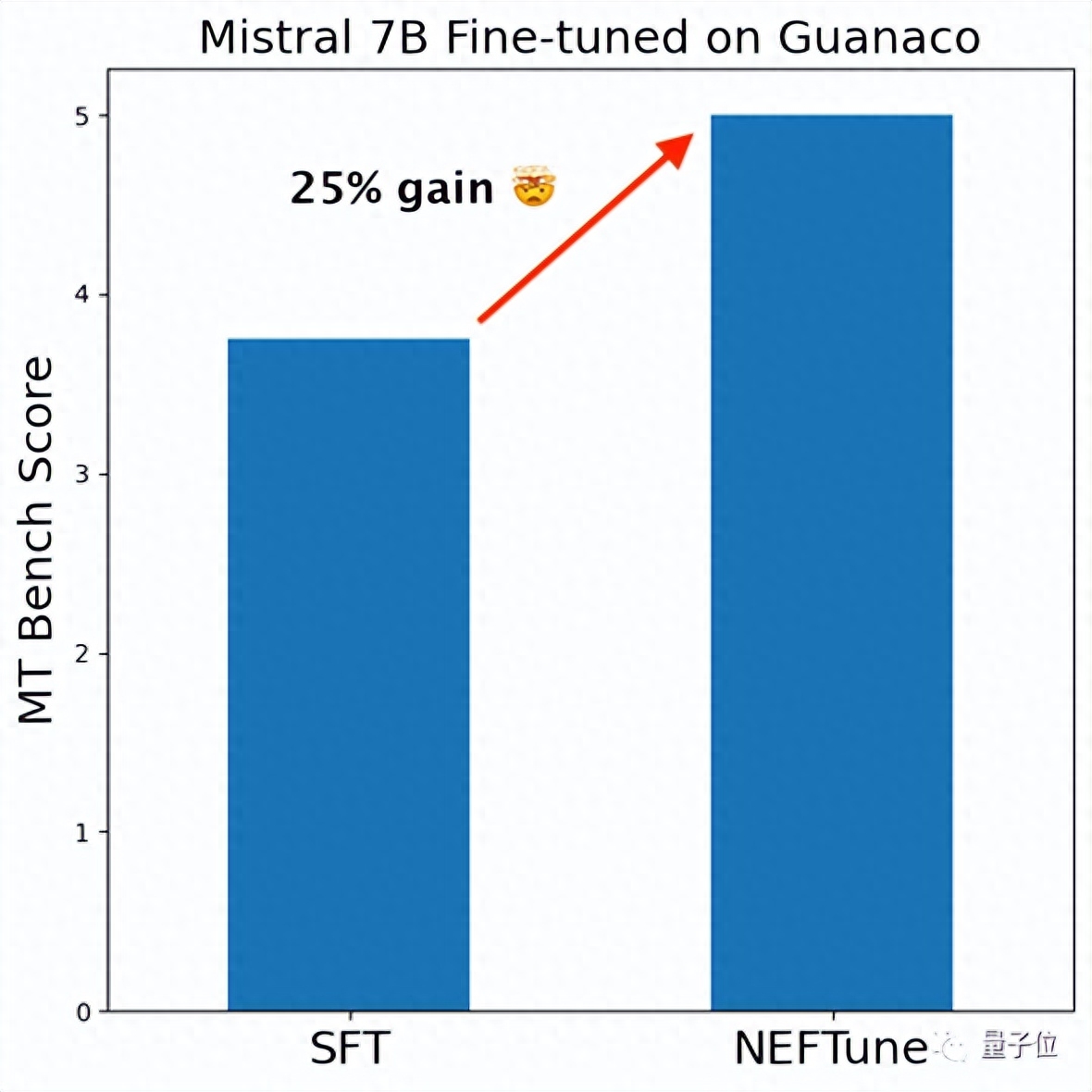
资源消耗没有显著增加 克雷西 发自 凹非寺量子位 | 公众号 QbitAI 大模型微调有“免费的午餐”了,只要一行代码就能让性能提升至少10%。 在7B参数量的Llama 2上甚至出现了性能翻倍的结果…
但人力消耗更低 克雷西 发自 凹非寺 量子位 | 公众号 QbitAI 说起现如今训大模型的核心方法,RLHF是绕不开的话题。 RLHF,即基于人类反馈的强化学习,无论是ChatGPT还是开源的LLa…
报告正文18页 克雷西 发自 凹非寺 量子位 | 公众号 QbitAI MIT哈佛斯坦福等机构在内的32位科学家联合指出: 被视作ChatGPT成功关键的RLHF,存在缺陷,而且分布在各个环节。 他们…
RLHF的一大缺点,终于被解决了! 西风 发自 凹非寺量子位 | 公众号 QbitAI RLHF(基于人类反馈的强化学习)的一大缺点,终于被解决了! 没错,虽然RLHF是大语言模型“核心技巧”之一,然…
CV/NLP通用 梦晨 发自 凹非寺量子位 | 公众号 QbitAI 开源大模型火爆,已有大小羊驼LLaMA、Vicuna等很多可选。 但这些羊驼们玩起来经常没有ChatGPT效果好,比如总说自己只是…
支持个性化微调 萧箫 发自 凹非寺量子位 | 公众号 QbitAI 基于Meta模型打造的轻量版ChatGPT,这就来啦? Meta宣布推出LLaMA才三天,业界就出现了把它打造成ChatGPT的开源…