
背后是专为开放世界打造的智能体
克雷西 发自 凹非寺
量子位 | 公众号 QbitAI
注意看,这个方块人正在快速思考面前几位“不速之客”的身份。

原来她是遇到了危险,意识到这一点之后,她马上开始在脑海中搜索策略。
最终,她的方案是先逃跑然后寻求帮助,并马上付诸行动。

与此同时,对面的人也在进行着和她一样的思考……

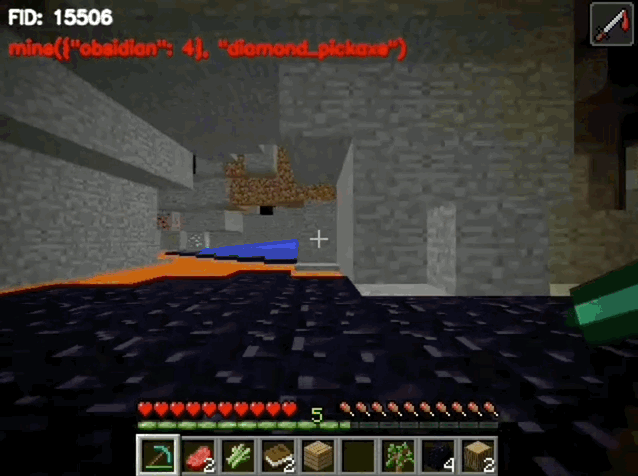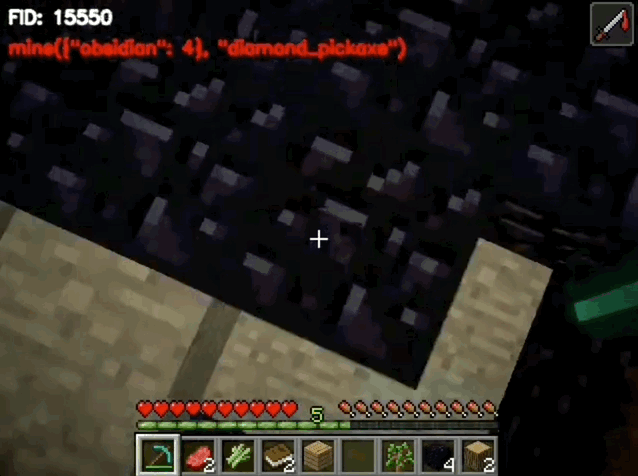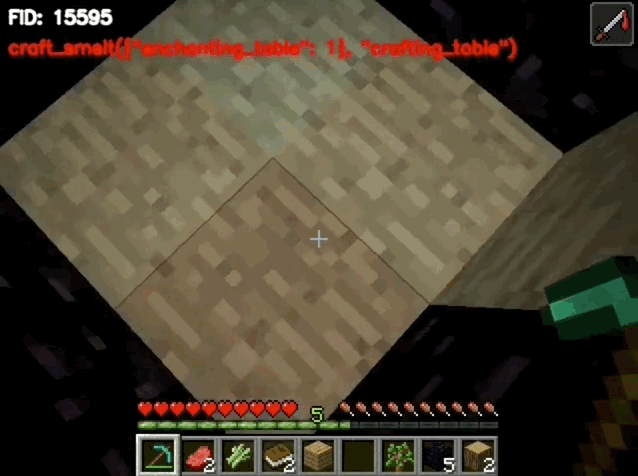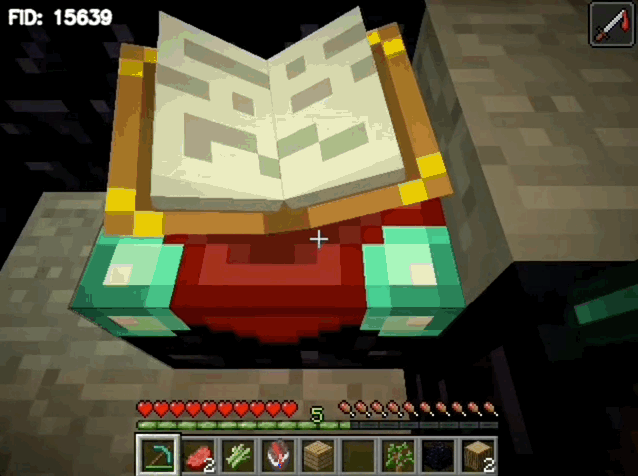
这样的一幅场景出现在了《我的世界》当中,而其中所有的人物都是由AI控制的。
他们有着各自的身份设定,比如前面提到的女孩是一个17岁、智勇双全的快递员。

他们拥有记忆和思考能力,在这个以《我的世界》为背景的小镇中像人类一样生活。
驱动他们的,是一款全新的、针对开放世界设计的、基于语言的AI角色扮演框架LARP。
这里的LA指的是Language Agent,同时LARP又是实时(Live Action)角色扮演的缩写,可谓是一语双关。
除了拥有更高的认知复杂度,相比于传统的智能体框架,LARP还缩小了智能体与开放世界游戏之间的差距——
这类游戏往往没有特定的“通关标准”,而是由玩家在其中自由探索,而传统的游戏智能体常被用来完成特定目标。
此外,LARP的重点是突出模拟,使得智能体的行为更接近人类,为此研究者甚至特意引入了遗忘机制。
那么,LARP具体如何实现?马上就来一探究竟。
多模块协同控制智能体
LARP的结构是模块化的,具体包括了认知、人格、记忆、决策等组成部分。
其中,记忆模块又由长期记忆、工作(短期)记忆和记忆处理系统三个部分组成。

流程上,角色观察到的环境等信息会以自然语言形式输入记忆处理模块,经过编码转换并结合提取到的长期记忆,形成工作记忆;
然后工作记忆会输入到决策模块,最终产生决策或对话内容。
决策模块的一个特点是会将一项大的目标拆解成子任务,同时利用其中的语言模型确定子任务的执行顺序。

模型所做出的决策,会通过环境交互模块调用API来执行,必要时还会调用回溯模块进行代码重建;
执行成功后,角色的新技能会被储存,成为新的长期记忆。

在长期记忆的提取的过程中,人物会根据观察到的内容进行自我提问,并通过逻辑语句、向量相似度和句子相似度三个维度进行查询,从而提取答案。
其中逻辑语句用于语义(semantic)记忆的查询,后两者则用来查询情景(episodic)记忆。
语义记忆是关于世界的一般性概念和事实知识,包含了游戏规则和相关世界观;情景记忆则是游戏中的具体事件,与特定场景和经历相关。
前者内容相对固定,而后者则会根据Agent的经历不断积累。

为了让LARP控制的智能体更像真人,研究团队还特意引入了随时间变化的遗忘机制。
当衰减参数σ超过一定阈值时,记忆提取会失败,从而模拟遗忘过程,σ的计算方式则是依据心理学定律设定的:
σ = αλN (1 + βt) – ψ
λ代表记忆的重要性程度,N表示提取次数,t代表最后一次提取后经过的时间,ψ是角色自身的遗忘速率,α和β为缩放参数
这一公式由心理学家Wayne Wickelgren提出,是对艾宾浩斯遗忘曲线的一个补充。
而在人物性格的塑造上,研究人员在体现不同性格的数据集上预训练出了基础模型,并用专门构建的指令数据集进行监督微调。
同时,团队还为角色的不同能力设计了多个数据集并训练出了低秩适配模型,并于基础模型动态整合,指导决策模块生成符合人设的内容。
同时,LARP中还设置了行动验证和冲突识别模块,确保模型为agent生成的内容受游戏环境数据和先验知识规范约束。

目前,LARP的GitHub页面已经建立,不过还处于空仓状态,代码暂未发布。

随着大模型研究的深入,智能体和群体智能实验如今已成AI研究最热门方向之一。
比如去年爆火的斯坦福AI小镇、清华推出的“AI游戏公司”和“AI狼人杀”,都让人们看到了多智能体协同的效益。
关于智能体的更多内容,量子位智库推出的《2023十大前沿科技报告中》也有详细介绍。
论文地址:
https://arxiv.org/abs/2312.17653


发评论,每天都得现金奖励!超多礼品等你来拿
登录 后,在评论区留言并审核通过后,即可获得现金奖励,奖励规则可见: 查看奖励规则