
自动驾驶的GPT时刻、iPhone时刻正在隐隐轰鸣
贾浩楠 发自 副驾寺智能车参考 | 公众号 AI4Auto
自动驾驶圈,竟也卷成这样!
3000元,比一次高档汽车贴膜服务,或一个洗车店年卡更便宜…
但它是现在最新量产L2+智能驾驶底层套件的成本价——

3000元,带1个前视相机、4个鱼眼相机、2个后角雷达、12个超声波雷达,算力5TOPS。能实现的却是高阶行泊一体智驾功能。
包括高速、城市快速路上的无图NOH (领航辅助) ,短距离记忆泊车。
系列产品还有5000、8000元版本,分别搭载不同价位车型,实现城市NOH功能。但同样突出超高功能体验下相对的超轻传感器方案、超低算力需求。

不是期货,而是明年就量产上车的现货。
L2++体验的入门门槛被卷到3000元成本,行业前所未见。
智驾落地新“卷王”,不是新面孔,而是之前业内一直有“最懂量产自动驾驶”之名的毫末智行。
智驾新卷王,高阶智驾极致性价比
量产智驾系统市场上很多,但在2023年这个时间点,明确区分“高阶”的,是是否具备领航辅助功能,也就是常说的NOA能力。
在领航辅助功能开启下,ADAS自主识别车道线、路上的其他目标,包括红绿灯在内的交通标志,实时制定驾驶策略。
最重要的,是根据导航信息自助规划路线,包括什么时候进出匝道、何时离开环岛,什么时候准备变道转弯等等。

简单的理解,就是用户不用直接承担驾驶任务,只作为安全员,负担大大减轻。
根据落地场景的复杂程度,NOA又分成高速和城市两种,对应着不同的方案和成本。
毫末智行的相关产品,叫做NOH。毫末智行董事长张凯,刚刚在AI Day上发布了支持量产NOH功能的最新智驾硬件方案产品。

最大的特征,总结成一句话:高速NOH起步标配,极致性价比前所未有。
HP170,成本3000元级“极致性价比”智驾硬件方案,但其实在行业平均水平中已经实现了高阶的功能能体验。实现高速上和城市快速路上的NOH功能,以及自主泊车能力,而且比常见的量产方案更近一步。
高速或城市快速路NOH,不依赖高精地图;而自主泊车能力,支持短距离记忆功能。
不依赖高精地图意味着更广泛更快速的城市能够解锁NOH;记忆泊车,则大大方便了有固定车位的用户。
硬件配置上,算力5TOPS,传感器方案标配1个前视相机、4个鱼眼相机、2个后角雷达、12个超声波雷达,灵活选装1个前视雷达和2个前角雷达。
毫末HP370,5000元级,实现的功能同样是“极致性价比”。除了高速、城市快速路的NOH,还支持城市内的记忆行车功能。泊车层面也有升级,实现免教学记忆泊车、智能绕障。

城市内记忆行车,就是今年流行的“通勤NOA”功能:系统可以通过训练,记住你常走的上下班路线,实现这一特定路段上的高阶领航辅助。这也是在成本和法规限制下,瞄准最高频需求推出的高阶智驾落地方案。
HP370底层算力32TOPS,传感器方案标配2个前视相机、2个侧视相机、1个后视相机、4鱼眼相机、1个前雷达、2个后角雷达、12个超声波雷达,灵活选装2个前角雷达。
最后还有一个HP570,可实现全场景城市无图NOH、全场景辅助泊车、全场景智能绕障、跨层免教学记忆泊车等功能。
功能拉满,体验最强,实现了“从P档到P档”的智能驾驶能力。这样的量产智驾天花板方案,之前在业界至少是数万元成本,毫末的“极致性价比”体现在官宣成本为8000元。

算力可选72TOPS和100TOPS两款芯片,传感器方案标配2个前视相机、4个侧视相机、1个后视相机、4个鱼眼相机、1个前雷达、12个超声波雷达,还支持选配1颗激光雷达。
简单科普一下智能驾驶量产落地目前的普遍情况:实现高速NOH,一般供应商方案至少需要20TOPS起步,平均数十TOPS的算力支持,传感器方案,也都在视觉和毫米波之外标配至少1个激光雷达。
而上升到城市NOH功能,则至少是254TOPS算力的英伟达Orin芯片起步,有的还要数颗,传感器一般是前向及补盲激光雷达至少3颗。

毫末智行董事长张凯这样评价这些方案:
毫末第二代HPilot的三款智驾产品把价格打到了3000元级、5000元级、8000元级的极致低位,同时性能都打了上去,让辅助驾驶产品成为最平民化的日用级消费品.
中低阶智驾便宜更好用,让高阶智驾好用更便宜
所以毫末量产智驾硬件方案的最大特征,也是行业“卷王”级成本的直接原因,就是摆脱了重传感器依赖,也自然用不到过大的算力支持。
但这种方案能保证可靠,并且达到量产条件的根本原因,还是要从毫末CEO顾维灏一季一度的AI Day“自动驾驶前沿技术分享”中找答案。
毫末为什么卷成这样?
毫末智行量产智驾硬件方案的最大不同,是无论3000、5000、8000元级的产品,激光雷达都是“非必要不增加”,突出以视觉为主的智能驾驶能力。
而激光雷达省下来的,不光是传感器采购的直接成本。
激光雷达除了贵(一个几千元),另一个不理想之处是其产生的点云图数据量大,回波噪声不好抑制,需要占用系统大量的计算资源。

想要低算力实现高功能,又不增加额外成本,就必须要在视觉能力上取得突破。
毫末给出了这样的直观数据。
截止目前,共计筛选出超过100亿帧互联网图片数据集,和480万段包含人驾行为的自动驾驶4D Clips数据(带有时间特征的连续视频片段),总学习时长超过103万小时。
乘用车用户辅助驾驶行驶里程已经接近9000万公里。注意这不是模拟仿真训练里程,而是毫末智行已经量产上车的产品,由用户实际使用产生的高价值数据。

上一次毫末公布相关数据是在200多天以前,学习时长和用户实际使用里程还分别是56万小时和4000万公里。
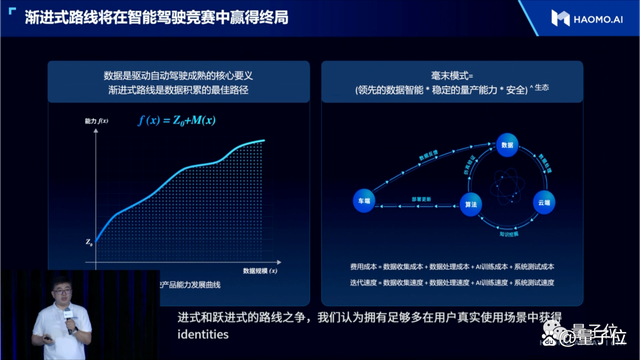
毫末在量产智驾方案上的快速降本卷到极致,本质是视觉自动驾驶能力的迭代进步。而迅速从行业内卷中脱颖而出,拿出史无前例的性价比方案,说明毫末AI能力进步的“加速度”已经今非昔比。
“大模型”引入自动驾驶,是核心原因,当然毫末依然是行业第一家。

DriveGPT,中文名雪湖·海若,是毫末的自动驾驶大模型技术体系。
DriveGPT在今年初提出来,是首先应用于自动驾驶认知决策模块,采用的是生成式预训练思路,只不过训练的数据从语言文本,变成了图片、视频等等自动驾驶数据。
实现过程分为3步:
首先在预训练阶段引入量产智能驾驶数据,训练出一个初始模型,相当于一个具备基本驾驶技能的AI司机。
然后再引入量产数据中高价值的用户接管片段(Clips形式),训练反馈模型。而不同Corner Case的依次迭代,相当于针对不同驾驶任务挑战分别强化AI司机的技能。
接下来就是通过强化学习的方法,使用反馈模型不断优化迭代初始模型。
所谓“生成”,反馈模型能够实时根据当前交通流情况,生成不同的针对性场景,训练初始模型。而完成迭代后,模型也能对同一任务目标生成不同的策略方案。

DriveGPT参数1200亿。DriveGPT模型本身始终部署在云端,直接“上车”还需要时间。但大模型本身可以对自动驾驶数据挖掘和训练起到加速作用,同时也能通过驾驶决策模型参数、效果的拟合学习,直接对车端用户,价值却是能够快速兑现。比如生成式模型能够做到智能捷径推荐、困难场景自主脱困、智能陪练等等。
公布200多天,DriveGPT又有了新的技术层面进展,这也是理解毫末“卷王”的核心。
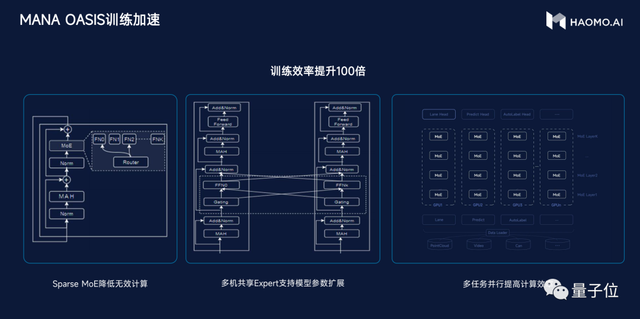
视觉感知网络架构,从之前ViT(Vision Transformer)为代表的大模型,升级到性能更强大的Swin Transformer大模型。从训练范式上,毫末率先采用基于大规模数据的自监督学习训练范式,采用Transformer大模型轻松“吃下”上百亿的图片,模型变得见多识广,泛化能力极强,逐渐可以识别万物。

现在,最新的大模型是采用视频生成的方式来训练,通过预测生成视频下一帧的方式,来构建4D表征空间,使得CV Backbone能够学到三维的几何结构、图片纹理、时序信息等全面的物理世界信息,相当于把整个世界装入到神经网络当中。
在视觉感知模型的架构、训练流程更新之外,毫末还做了一件事,就是引入外部的大模型,使得自动驾驶在感知和认知层面,具备通用能力,可以识别万物,具有世界知识,能力媲美人类老司机。
感知模型方面,引入NeRF技术,通过预测视频下一帧的自监督方式来构建4D编码空间,即将一个Clips序列的前K帧的部分输入模型,用NeRF(神经辐射场)渲染出后续H帧。

这样通用感知大模型就可以分为3个关键的模块:4D编码器、多模态教师、NeRF渲染器。其中,4D编码器将视频中的时空特征编码到一个4D特征空间里;多模态教师模型是一个预训练好的多模态大模型,可以将视觉特征对齐到文本语义特征。
NeRF渲染器则通过预测未来视频的方式,用来监督4D 特征空间中对世界的感知能力。通过这种方法,毫末DriveGPT构建起更有效、更见多识广的自动驾驶通用感知大模型,实现在一个模型中同时学习到空间的三维几何结构、语义分割和纹理信息,具备识别万物的能力,也由此更好地完成目标检测、目标跟踪、深度预测等各类感知任务。
认知层面,一个老司机不仅仅只会操控汽车,还必须具备人类社会的常识,懂得这个世界的普遍规律,或者说世界知识。但这种世界知识仅仅通过自动驾驶数据是难以学到的,而大语言模型LLM已经学习并压缩了人类社会的全部知识,所以引入大语言模型来辅助驾驶决策是一个非常有效的途径。

为了让LLM更好地适配自动驾驶任务,毫末采用自动驾驶行业数据,对LLM进行了微调,使得LLM能看懂驾驶环境、能解释驾驶行为,做出更优的驾驶决策。
这样,认知大模型除了获得感知大模型看到的物理世界信息之外,也能像老司机一样具备社会常识、知道这个世界各种现象背后的物理知识,从而像老司机一样驾驶。
,时长01:48
这些技术层面的创新,让毫末的模型结构、训练方式,以及对世界理解认知层面能力提升,而服务的主要对象,是视觉感知能力,也实实在在的反应在量产方案的降本增效上。
比如将视觉感知能力引入到泊车场景中,并结合视觉BEV的感知框架,使毫末视觉感知模型使用鱼眼相机可以识别墙、柱子、车辆等各类型的边界轮廓,形成360度的全视野动态感知,可以做到在15米范围内达到30cm的测量精度,2米内精度可以高于10cm。这样的精度可实现用视觉取代USS,从而进一步降低整体智驾方案成本。

再比如,毫末城市NOH可以在城市道路场景中,在时速最高70公里的50米距离外,就能检测到大概高度为35cm的小目标障碍物,可以做到100%的成功绕障或刹停。这就是摆脱激光雷达依赖的一个体现。
为什么毫末能在量产商业化上卷到如此程度?
毫末智行CEO顾维灏给出的解答是:
大模型、大数据、大算力,成为自动驾驶公司迈入3.0时代的关键标志。在感知阶段,通过海量的数据训练感知基础模型,学习并认识客观世界的各种物体;在认知阶段,则通过海量司机的驾驶行为数据,来学习驾驶常识,通过数据驱动的方式不断迭代并提升整个系统的能力水平。
很庆幸,毫末从一开始就在为自动驾驶3.0时代作准备。在感知、认知、智算中心的建设上,毫末都是按照数据驱动的方式建设的
与主机厂紧密的联系让毫末对工程化、成本控制理解深刻,敏锐的捕捉自动驾驶最先进最前沿技术,并率先落地应用。
如何评价?
毫末智行如今要加上一个新的标签:落地最卷的自动驾驶公司。
之前它有“量产自动驾驶第一名”的评价,现在也正在代表着量产自动驾驶产品方案、落地趋势的benchmark:
Transformer的引入和计算基础设施建设的成熟,使高阶智能驾驶落地竞争,由独特价值提供,转向增量价值的竞争。
毫末迅速适应了这样的变化拿出3000元成本的产品,意味着用户端可以在20万以下甚至10万级的乘用车上标配高阶智能驾驶,真正享受黑科技的红利。所以是高阶自动驾驶开始普及的信号和里程碑。
毫末智行本身,成为量产自动驾新卷王,核心原因是它代表了自动驾驶最先进前沿技术的应用方向。从最早引入Transfomer、到大模型率先应用,以及现在在训练端引入类似LoRA图片生成模型之类的技术……这些技术在毫末这里,还能快速产生价值,反应在落地量产的产品迭代中。
这也让毫末一季一度的AI DAY,成为了自动驾驶技术方向上风行标性质的活动。

不夸张地说,如果想要保持对自动驾驶技术最核心的关注,最高效的方式就是关注好毫末每个季度的AI DAY。
之前还有特斯拉AI DAY、自动驾驶日,但因为今年的跳票,业内响亮的“学习机会”就只剩毫末了。
而在背后更加值得注意的,是毫末智行代表的自动驾驶技术体系的变革,正越来越深刻的理解并应用大语言模型的范式和具体思路。
自动驾驶的GPT时刻、iPhone时刻正在隐隐轰鸣。
这样的转折,可能并不是在实验室中实现然后再向用户推广。更有可能是毫末、特斯拉这样的渐进式量产自动驾驶玩家,在持续的交付和迭代的商业运营过程中率先突破。


发评论,每天都得现金奖励!超多礼品等你来拿
登录 后,在评论区留言并审核通过后,即可获得现金奖励,奖励规则可见: 查看奖励规则