
利用环境交互做动作追踪
西风 发自 凹非寺
量子位 | 公众号 QbitAI
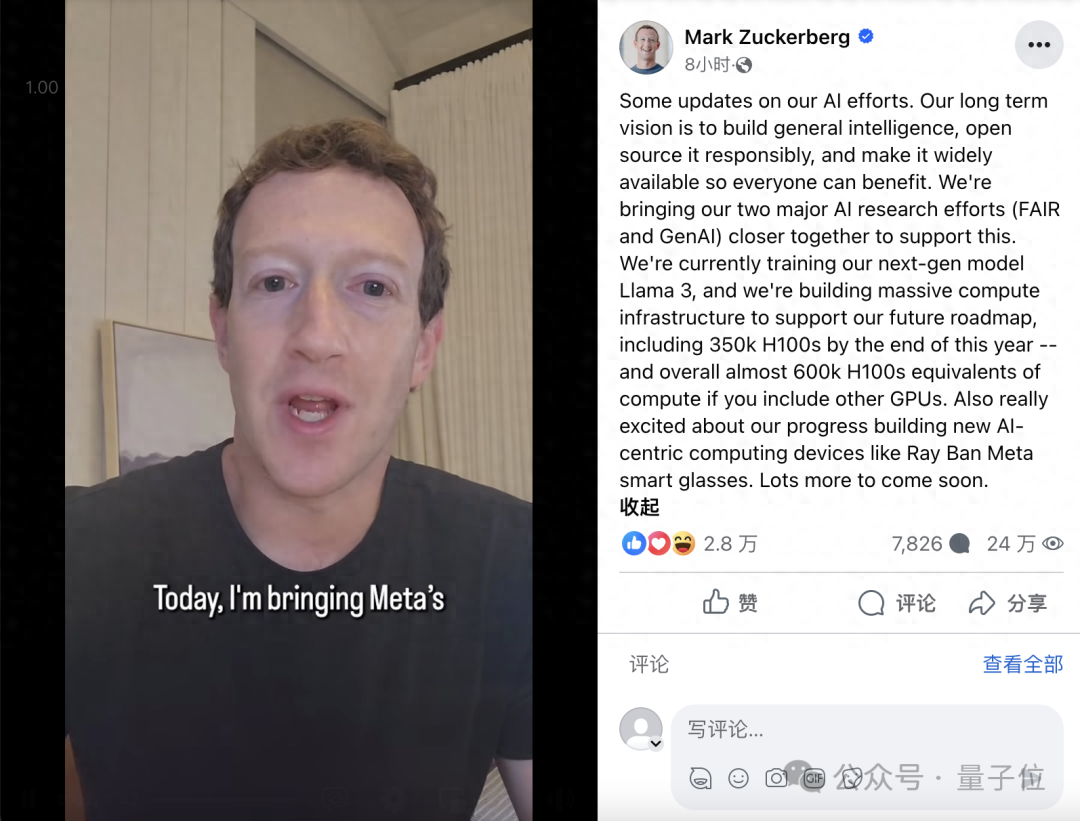
这不,就在最新被SIGGRAPH 2023顶会收录的研究里,研究人员展示:
仅凭Quest传感器和周围物体环境的交互,就可以捕捉一个人的全身运动!
即使是和复杂环境进行交互也不在话下。
输入的时候还是这样婶儿的,只有三个坐标架(没有摄像头):

加上虚拟角色后,胳膊腿的动作都有了(绿点是环境高度):

看到腿部的动作效果,网友直接裂开:
这腿部的估计把我惊呆了!

还没完!在没有任何关于下半身信息的情况下,它还可以踩箱子,跨过障碍物,精准跟踪人体动作。

通过物理模拟,无需任何后期处理,就能够生成效果不错的互动场景:

一个传感器也能行!去掉手部的两个传感器后,虽然手的动作是随机的,但走起路来也还是有模有样:

网友看完后满脸不可思议:
有没有考虑与Metahuman系统结合,这样用户就可以使用简单的设备在家中创作出包含身体和面部表情完整的数字人动画了!

目前,现有的大多数运动跟踪方法除了脚与地面的接触外,都尽量避免了与环境的交互。
那么,这项研究是怎样利用环境交互进行运动跟踪的呢?
用包含环境交互的数据来训练
我们日常生活中与环境进行交互是不可避免的。
由首尔大学(SNU)和Meta Reality Labs Research的研究人员共同完成的这项工作,通过强化学习展示了如果将传感器与物理模拟和环境观测相结合,即使在高度受限制的环境中,也能复现逼真的全身动作姿势。

要做到这一点,首先需要考虑三种方法,包括:
合成具有交互的动作、从稀疏传感器输入进行运动学跟踪以及基于物理的运动追踪。

本文研究人员使用的策略只需要头显和手柄的姿势作为输入,没有关于下半身的信息,并且没有借助人力来稳定虚拟角色。
该研究中物理模拟可以自动执行跟踪动作姿态所需的各种约束,使其能够实现高质量的交互动作,而不会出现常见的穿透或接触滑动等问题。
并且使用深度强化学习(Deep RL)学习控制策略,用减小模拟的虚拟角色和用户输入之间的差异来使误差最小化。

如上图所示,虚拟的仿真角色具有32个自由度(degrees of freedom)和18个关节,并由关节力矩驱动,环境物体也用一些基本几何形状进行了仿真复制。
真人在与环境物体之间发生接触时,具体时间和位置将会被标记出来,被用作监督信息。
这样将场景观察结果纳入策略中,就可以利用环境进行运动跟踪。比如说,坐在椅子上会产生椅子的反作用力,从而可以知道要将腿部抬起;当踩在放在地面上的盒子时,也会有盒子的反作用力;还可以通过接触后的反作用力来操纵物体。

有意地与环境产生接触力,有利于跟踪。但另一方面,如果接触会干扰追踪,控制策略也可以避免与环境的接触。
比如在虚拟仿真环境中放置了虚拟盒子。控制策略可以学会通过高度图(绿点)观察周围的场景,并在跟踪人的传感器数据时抬高腿以避开障碍物。

当然要达到这种效果,还需要注意三个关键点:适当的环境观察表示、训练中的接触奖励(不仅仅包括脚部,还包括其他身体部位),以及训练过程中对象位置的随机变化。
研究人员注意到,在没有接触奖励的情况下,成功率会明显降低。在没有场景随机化的情况下,性能也会显著下降。

坐下,起不来
虽然在大多数情况下,这项研究所展示的动作跟踪效果很好,但也有跟踪失败的情况:


对于从地板上起身这样的任务,由于没有没有使用任何人为力量,该控制策略似乎很难学好这种需要仔细协调接触的行为。
并且,虚拟角色有时会失去平衡,一旦摔倒中断,很可能无法继续爬起来跟踪。

还有一点不得不提,当前的系统需要为每种交互类型训练单独的策略。
研究人员表示:
理想情况是能够学习一个涵盖更广泛动作库的单一跟踪器。这可能需要更复杂的神经网络模型,如专家混合模型,或更长时间的训练和更大规模的数据集。
另一个有前景的方向是将我们的系统扩展到包括动态移动物体的未知场景。在线系统识别可以作为系统的一部分进行结合。
参考链接:
[1]https://arxiv.org/abs/2306.05666(论文地址)
[2]https://twitter.com/awinkler_/status/1673133836585291776
发评论,每天都得现金奖励!超多礼品等你来拿
登录 后,在评论区留言并审核通过后,即可获得现金奖励,奖励规则可见: 查看奖励规则