
成功前大家都在赌
色 萧箫 发自 凹非寺
量子位 | 公众号 QbitAI
这几天,一张名为“大语言模型进化树”的动图在学术圈疯转:

它清晰梳理了2018到2023五年间所有的大语言模型“代表作”,并将这些模型架构分成三大类,进化结果一目了然:
业界颇具影响力的谷歌BERT,从一开始就走向了“岔路”,如今在生成AI领域已濒临淘汰;
与谷歌和Meta“多线布局”不同,OpenAI从GPT-1开始,就坚定其中一条技术路线,如今成功走在这条路线的最前沿……
有网友调侃,在大模型没有成功之前,大家都只是在参与一场“赌局”:

还有网友感叹,两年后会进化成什么样子简直不敢想象。

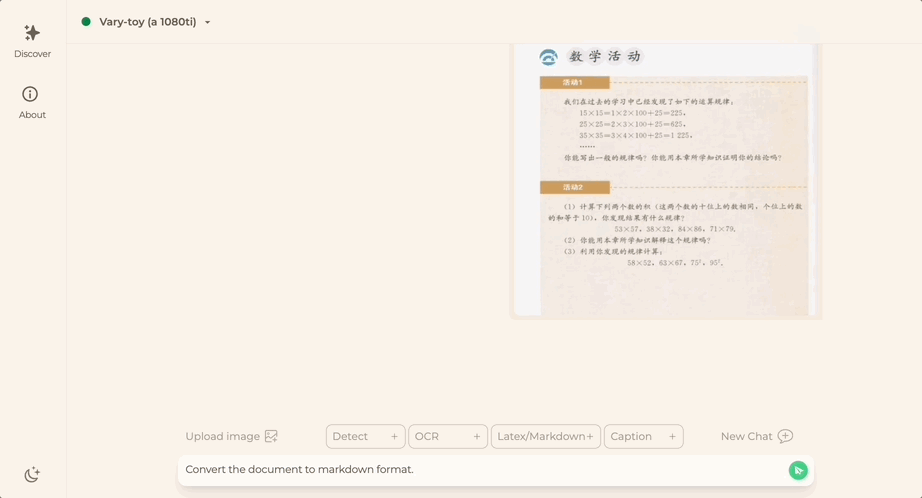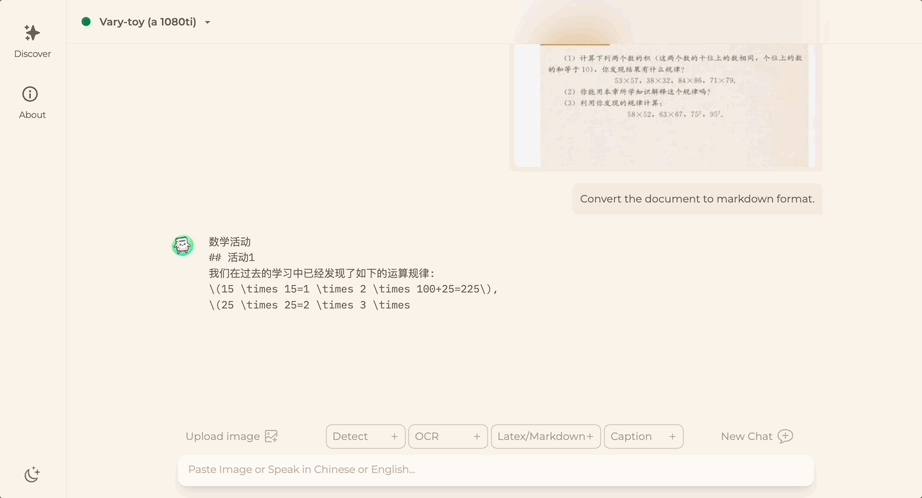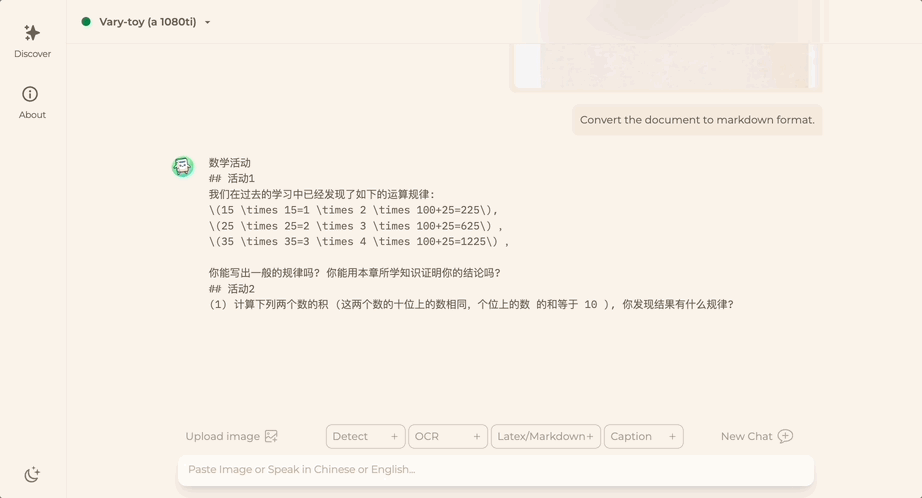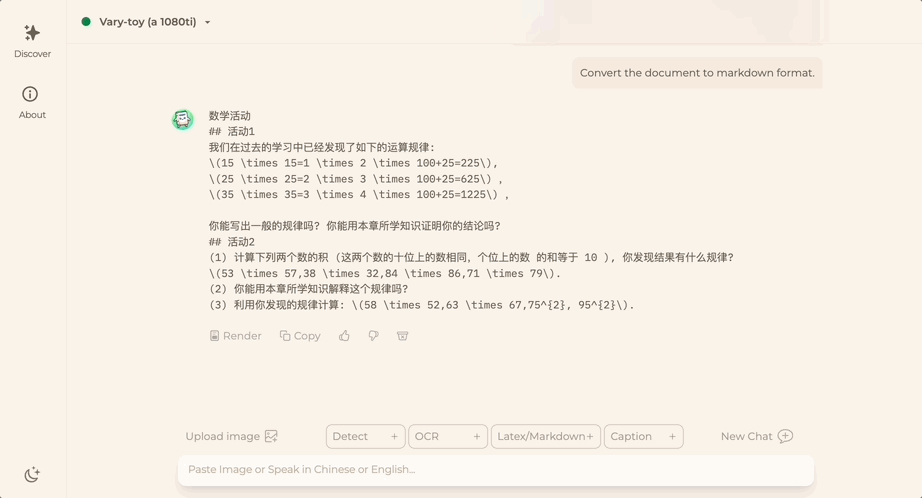
我们扒了扒,发现这张图原来来自于最近一篇爆火的综述论文《在实践中利用大模型的力量》:

论文不仅详细阐述了现代大语言模型LLM这5年的发展历程,还针对当下大伙儿最焦虑的“如何选用LLM”这一关键问题,给出了详细解答。
比如在自然语言理解任务中,微调模型通常是比LLM更好的选择,不过LLM可以提供强大的泛化能力;而在知识型密集任务中,LLM学到了更丰富的现实世界知识,所以比微调模型更适合。
所有的一切都被浓缩成了一张图,简直不要太清晰明了。

整体来说,论文分为三个部分,对大语言模型是如何发展的(模型实用指南)、大模型性能究竟受什么影响(数据实用指南)、以及什么场景用什么类型的模型(NLP任务实用指南)这几个重点分别进行了详细介绍。
我们逐个来看看。
“BERT派”和“GPT派”二分天下
首先来解读一下上面的LLM发展进化史,也就是论文中的《模型实用指南》。
根据论文,大模型发展主要可以分为两类,作者们将它命名为“BERT派”和“GPT派”:

其中,“BERT派”的特征是模型中有编码器架构,具体分为编解码器(Encoder-Decoder)和只有编码器(Encoder-only)两类架构;
“GPT派”则主张扔掉编码器,架构中只保留解码器(Decoder-only)。
最初“BERT派”占据上风。但以BERT为代表的Encoder-only路线发展惨淡,相关研究到2020年就逐渐消失。
随后,GPT-3的出现,彻底转变了大语言模型领域的风向,OpenAI为代表的“GPT派”开始发展壮大,并成为如今LLM中发展最顺利的一支。
根据这一想法,作者们将它做成了一张完整的树状图,记录了这些年大模型各大路线的发展兴衰。
而这张图也成为了谷歌和OpenAI在大模型这场战争的“记录图”。
显然,谷歌在只有解码器、只有编码器和编解码器三个方向都有不少布局,然而如今,大模型依旧是“一条路走到头”、只搞Decoder-Only的OpenAI占据上风:
△图中有个bug,ALBERT是谷歌开发的
然而与此相对,我们也能发现,大模型整体呈现出“越来越封闭”的状态,而这很大程度上要归功于“Open”AI的表现。
不过在这些大厂里,Meta开源还是做得不错的,只有几十人的HuggingFace也成了重要力量:

当然,这并不意味着“BERT派”已经整体落于下风,毕竟编解码器这个分支发展得也还不错,包括清华GLM和谷歌T5都是这个领域的代表开源模型。
未来这几大LLM路线的发展速度是否会发生变化,还是一个未知数。

那么,影响大模型性能的关键因素究竟是什么呢?
如何判断LLM性能好坏?
论文认为,影响LLM性能的关键因素依旧是数据。
什么样的数据?
根据LLM不同阶段,数据类型也主要分为三种,包括预训练数据、微调数据和测试/用户数据。
数据类型不同,对模型的影响作用也并不一样,甚至能直接决定大模型的最佳适用范围,论文在《数据实用指南》有具体阐述。
首先是预训练数据。它相当于大语言模型的“基底”,既决定了LLM的“语言功底”,又会极大影响LLM在下游任务的表现。
一方面是LLM的“语言功底”,指大语言模型对单词的知识、语法、句法和语义的理解能力,以及上下文和生成连续文本的能力。
为了锻炼LLM这部分能力,数据需要全面展现人类知识、语言和文化。
另一方面是LLM在下游任务的表现,这部分对于如何选择LLM应用思路起着至关重要的作用。
为了锻炼LLM这部分能力,需要考虑预训练数据的多样性,尤其是完成特定下游任务需要的“特定”数据,例如用社交媒体数据训练出的LLM问答能力、用代码数据训练出的LLM逻辑和代码填充能力等。
其次是微调数据。这部分数据往往被用于“调试”特定任务性能,具体又分为零标注数据、少量标注数据和大量标注数据。
其中,零标注数据通常被用于零次学习(Zero-Shot Learning)中,即希望大模型能完成之前没见过的任务,具备更强的“推理能力”;
少量标注数据主要用于引导大模型出现推理能力的同时,更好地提升某些少样本任务的性能,类似方法有元学习和迁移学习等;
大量标注数据则用于提升特定任务性能,当然这种情况下,微调模型和LLM都可以考虑使用它。
最后是测试/用户数据。这部分数据用于缩小模型训练效果和用户需求之间的差距,典型方法包括RLHF,即人类反馈强化学习,能显著增强LLM的泛化能力。
了解了三类数据对模型的不同影响,如何在实际任务中,选择对应的模型呢?
LLM还是微调模型?六大具体情况分析
接下来是本文重点部分:《NLP任务实用指南》。
在实际下游任务中,选择直接用只经过预训练的大模型LLM,还是用在此基础上经过特定数据集微调后的较小模型?
具体情况具体分析。
首先来看传统自然语言理解(NLU)任务,包括文本分类、用于知识图构建的命名实体识别(NER),以及自然语言推理entailment prediction等。
先上结论:
在这类任务中,微调模型通常是比LLM更好的选择,不过LLM可以提供强大的泛化能力。
具体而言,在大多数自然语言理解任务中,如果这些任务带有丰富的、注释良好的数据,并且在测试集上包含很少的分布外示例,那么微调模型性能更好。
不过对于不同的任务和数据集,两者的差距还不完全一样。
比如在文本分类中,LLM大多只是略逊于微调模型;而在情绪分析上,LLM和微调模型表现一样好;毒性检测上,则所有LLM都很差。
作者认为,这种结果一是跟LLM的指令或prompt设计有关,二是微调模型的能力上限确实还很高。
当然,也有LLM擅长的,一个是杂项文本分类,需要处理各种没有明确关联的内容,更接近真实世界;另一个是对抗性自然语言推理(ANLI)。LLM对这种具有分布外和注释稀疏的数据有良好的泛化能力,微调模型不行。

其次是生成任务,包括两种:
第一种侧重于对输入文本进行加工转换,比如写摘要和机器翻译;第二种是开放式生成类,根据用户需求从头生成文本,比如写故事、写代码等。
这类任务要求模型理解能力好,以及有创造性,LLM绝大多数情况都表现更好。
具体而言,对于写摘要来说,尽管机器评估结果显示LLM并没有比微调更有优势,但在人类评估上它赢了。
在机器翻译上,尽管LLM平均性能略低于一些商业翻译工具,但它尤其擅长将一些预训练可能都没见过的小语种翻译成英语,比如罗马尼亚语、罗曼什语、加利西亚语等等。
而开放式生成中,目前我们见到的很多作品都是基于没有经过微调的LLM生成的,比如GPT-4,其实力可见一斑,不用多说。

第三是知识密集型任务,这类任务强烈依赖背景知识、特定领域专业知识或现实世界常识等,要解决它们早已超出简单的模式识别或语法分析的范畴。
同样,先说结论:
(1)LLM因具有丰富的现实世界知识所以更擅长知识密集型任务。
(2)当需求与其所学知识不匹配时,或者面临只需要上下文知识的任务时,LLM会遇到困难。在这种情况下,微调模型可以顶上。
具体而言,在一般的知识密集型任务中,LLM在几乎所有数据集上都表现更好,这是数十亿的训练token和参数给它带来的。
比如在谷歌提出的大模型新基准Big bench中的大多数任务中,它的性能优于人类的平均水平,某些情况下,甚至可以与人类的最佳性能相媲美,比如提供有关印度教神话的事实、从元素周期表中预测元素名称等。
不过,Big bench其中一些任务比如要求模型说出ASCII艺术表示的数字,或者是重新定义了一个公共符号,要求模型在原始含义和从定义中派生的含义之间进行选择时,LLM表现不如微调模型,甚至比随机猜测还要差。

这是因为这类任务需要的知识与现实世界无关。
需要注意的是,如果“闭卷任务变成开卷”,给模型赋予检索增强的能力,尺寸更小的微调模型的表现会比LLM更好。
在以上三类任务之外,作者还详细分析了LLM扩展(Scaling)方面的知识,以及我们在上面提及任务之外的其他任务和现实世界真实任务上的选择。
这里就不一一展开了,奉上结论。
LLM扩展:
当模型规模呈指数级增长时,LLM将变得特别擅长算术推理和常识推理;
不过在许多情况下,由于人类理解还有限,扩大规模后的LLM性能并不会随之稳步提升。
其他未归类的杂项任务:
在与LLM的预训练目标和数据相去甚远的任务中,微调模型或特定模型仍有空间;
LLM在模仿人类、数据评注和生成方面非常出色,也可以用于NLP任务中的质量评估,并具有可解释性的优点。
现实任务:
这类任务面临的挑战包括嘈杂/非结构化的输入、用户的请求可能包含多个隐含意图等。
与微调模型相比,LLM更适合处理这些场景。然而,在现实世界中评估模型的有效性仍然是一个悬而未决的问题。
最后,还有一些总体准则:
如果对成本敏感或有严格的延迟要求,考虑轻型的微调模型,而不是LLM;
LLM的零样本方法无法从特定任务数据集进行shortcut learning,但微调模型可以;
高度重视与LLM相关的安全问题,因为LLM会产生潜在有害或偏见输出。
Over。
看完上面这些,是不是觉得条条框框有些不好记?
别急,如开头所述,作者已经将它们全部浓缩成了一张思维导图,照着它来分析就好了!(手动狗头)

8位华人作者
本文作者一共8位,全部是华人,分别来自亚马逊、得克萨斯农工大学和莱斯大学,其中5人是共同一作。
共同一作杨靖锋(Jingfeng Yang),目前是亚马逊应用研究科学家,本科毕业于北大,硕士毕业于佐治亚理工学院,研究方向是NLP和机器学习。
此前,他还写过一篇关于GPT-3和GPT-3.5的复现和使用指南,详细解读了为什么关于GPT-3的复现大部分会失败、以及使用GPT-3.5和ChatGPT的最佳方式。
共同一作靳弘业(Hongye Jin),目前是得克萨斯农工大学在读博士生,本科毕业于北京大学,研究方向是机器学习等。
共同一作Ruixiang Tang,莱斯大学计算机科学四年级博士生,本科毕业于清华大学自动化系,研究方向是可信任AI,包括机器学习的可解释性、公平性和鲁棒性。
共同一作Xiaotian Han,得克萨斯农工大学四年级博士生,本科毕业于山东大学通信工程,于北邮拿到计算机科学硕士学位,研究兴趣是数据挖掘和机器学习。
共同一作Qizhang Feng,得克萨斯农工大学博士生,本科毕业于华中科技大学,硕士毕业于杜克大学,研究方向是机器学习。
此外,亚马逊应用研究科学家姜昊茗(Haoming Jiang)、亚马逊应用科学主管Bing Yin和莱斯大学助理教授Xia Hu也参与了这次研究。
论文地址:
https://arxiv.org/abs/2304.13712
大模型实用指南(持续更新中):
https://github.com/Mooler0410/LLMsPracticalGuide
参考链接:
[1]https://twitter.com/indigo11/status/1651427761813327872
[2]https://twitter.com/JingfengY/status/1651404401817567234

发评论,每天都得现金奖励!超多礼品等你来拿
登录 后,在评论区留言并审核通过后,即可获得现金奖励,奖励规则可见: 查看奖励规则